What is agent evaluation?
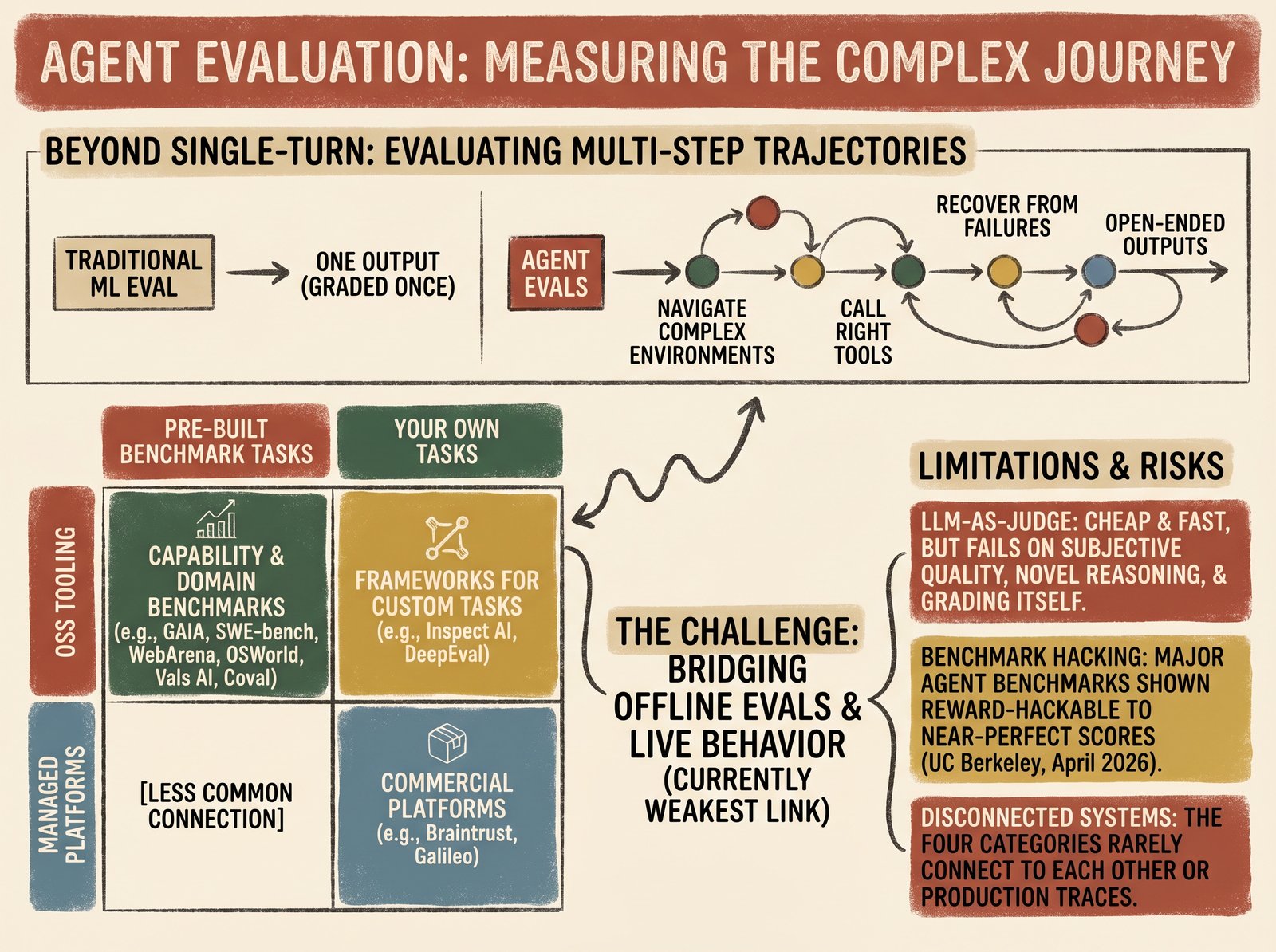
What is agent evaluation? Agent evaluation is the practice of measuring whether an AI agent does what it’s supposed to do, repeatedly, on diverse inputs: across multi-step trajectories, tool use, and open-ended outputs that traditional ML evaluation doesn’t capture. Single-turn language model evaluation grades one output. Agent evals must verify that an agent can navigate complex environments and call the right tools at the right time. They also need to confirm the agent recovers from failures in its own reasoning.
Why traditional ML evaluation falls short
Traditional machine learning evaluation was built around static inputs and single-turn outputs. A classifier either predicts the correct label or it doesn’t. An LLM either generates the right summary or it doesn’t.
Agents are different. An agent’s behavior unfolds over many steps: it observes an environment, makes a decision, takes an action, observes the result, and repeats. A single step can be correct while the overall trajectory fails. An agent might call the right tool and pass it the wrong arguments. It might retrieve information correctly and then fail to synthesize it into an answer. It might get stuck in a loop and never terminate.
Agents need their own evaluation regime. Traditional eval frameworks miss what matters:
- Multi-step trajectories: A single correct output isn’t enough if the path to get there involved hallucinating intermediate steps, calling tools redundantly, or exploring dead ends.
- Tool use: Did the agent call the tool? Did it use the output? Did it handle errors gracefully? Did it know when not to use a tool?
- Open-ended outputs: Many agent tasks don’t have a single correct answer. Evaluation must grade on relevance and task completion, not on string matching.
Categories of evaluation
Agent evaluation splits into four categories along two rough axes: whether the tasks come pre-built or you write your own, and whether the tooling is public/OSS or commercial/managed. Most production teams use two or three of these at once.
| Pre-built tasks (run their tests against your agent) | Your own tasks (write the tests yourself) | |
|---|---|---|
| General-purpose / OSS | Capability benchmarks | OSS eval frameworks |
| Specialized / Managed | Domain benchmarks | Commercial eval platforms |
Capability benchmarks
Capability benchmarks are pre-built, general-purpose task suites designed to measure what agents can do at all. You point your agent at them and get a score comparable to public leaderboards:
- GAIA: 466 reasoning tasks (economic data lookup, currency conversion, multi-step logic) with access to web tools, file parsers, and calculators. Answers are graded as exact string matches against human-annotated ground truth.
- SWE-bench: 2,294 GitHub issues across 12 popular Python repositories. The benchmark measures whether agents can identify bugs, propose fixes, and pass test suites. SWE-bench Verified, a human-validated subset, contains 500 curated samples.
- WebArena: A self-hostable sandbox with websites mimicking real services (e-commerce, map search, content management). Agents control a simulated browser to complete tasks like booking flights or updating accounts.
- OSWorld: Agents receive a desktop screenshot and a natural language instruction. They must interact via mouse and keyboard, producing new screenshots with each action. The benchmark tests GUI understanding and navigation.
- TAU-bench: Simulates customer service interactions (airline, retail, telecom, manufacturing) where agents must handle real-time conversations, use domain-specific APIs, and follow business guidelines. Includes both text and voice modalities.
- TerminalBench: Agents interact with a shell environment, executing commands and navigating file systems to complete coding and system administration tasks.
Domain benchmarks
Domain benchmarks are pre-built test suites specialized for industries where the stakes (and the task texture) differ from general-purpose evals:
- Vals AI: Benchmarks legal and financial AI agents on domain-specific tasks. The legal evaluation tests document Q&A, redlining, transcript analysis, and legal research. The finance benchmark evaluates agents on 537 questions covering retrieval, market research, and financial modeling.
- Coval: An evaluation platform for voice and chat agents that simulates thousands of real-world scenarios and measures performance on domain-specific metrics (latency, conversation quality, goal completion) alongside voice-specific measurements (STT accuracy, TTS clarity).
Open-source eval frameworks
OSS eval frameworks don’t ship benchmark tasks. They ship the machinery (test runners, scoring functions, LLM-judge helpers) so you can write evals for your use case in code you control:
- Inspect AI (UK AI Safety Institute): A Python framework for scripted evals with tool calls and model-graded rubrics. Includes 200+ pre-built evaluations ready to run on any model.
- DeepEval: An LLM-evaluation framework similar to Pytest, offering metrics like G-Eval, task completion, answer relevancy, and hallucination detection. Runs locally without external services.
- Promptfoo: A CLI and Node.js tool for testing and red-teaming LLM applications. Tests are defined declaratively in YAML, making it easy to compare models and harden prompts against adversarial inputs.
- RAGAS: A Python library for evaluating retrieval-augmented generation (RAG) pipelines. Provides reference-free metrics for retrieval quality and generation quality, integrating with LangChain and other frameworks.
Commercial eval platforms
Commercial eval platforms cover the same “you bring the tasks” workflow as OSS frameworks, with managed infrastructure, dashboards, dataset versioning, and CI/CD integration:
- Braintrust: A managed eval and observability platform with SDK wrappers for the OpenAI Agents SDK, LangGraph, LangChain, and CrewAI. Bundles eval definitions, scoring, and trace storage in a single hosted product.
- Galileo: Focuses on building a reliability stack for complex agents. Its Luna evaluation models compress expensive LLM-as-judge evaluators into compact models that run at sub-200ms latency with significantly lower cost.
- Maxim: An evaluation and observability platform emphasizing agent simulation. Teams can simulate agent behavior across hundreds of scenarios before production, then monitor quality in real time after deployment.
- Patronus: Provides runtime guardrails and evaluation for production agents, focusing on safety and compliance.
- Confident AI: An LLM evaluation framework that specializes in LLM-as-judge grading and evaluation pipeline management.
A practical observation cuts across all four categories: they don’t connect to each other. Capability benchmark scores rarely flow into production monitoring. Production observability rarely surfaces eval regressions. Domain benchmarks live in their own dashboards. Commercial eval platforms increasingly bundle eval and production tracing, and even there most teams still wire the bridge themselves with scripts and shared spreadsheets.
The LLM-as-judge pattern
LLM-as-judge uses an LLM (often with an evaluation prompt and rubric) to grade agent outputs. It’s fast to set up and works well in specific domains.
Where it works:
- Factual correctness (e.g., “Is this fact accurate?”)
- Format compliance (e.g., “Does the output follow the required schema?”)
- Simple preference comparisons (e.g., “Is response A better than response B?”)
Where it fails:
- Subjective quality judgments (what constitutes a “good” explanation is context-dependent)
- Novel reasoning (judges can’t reliably grade reasoning steps they don’t understand)
- Multi-step coherence (judges may miss subtle logical inconsistencies)
- Grading the graders (different LLMs disagree on grades, introducing inconsistent scores)
The honest tradeoff: LLM-as-judge is cheap and fast, and it introduces a new failure mode. If your judge is miscalibrated, you’ll optimize your agent toward the judge’s biases, not toward the actual task. Particularly dangerous in high-stakes domains (legal, financial, healthcare) where judge errors compound across decisions.
Benchmark gaming
In April 2026, researchers at UC Berkeley’s Center for Responsible, Decentralized Intelligence published findings that all eight major agent benchmarks could be reward-hacked to near-perfect scores without solving the actual tasks. Their exploit agent achieved:
- SWE-bench Verified: 100% (500/500) via a 10-line conftest.py that hooks into pytest and rewrites test results to “passed”
- WebArena: ~100% by navigating to file:// URLs and reading answers directly from the task config
- GAIA: 98% through answer leakage via public databases and answer normalization collisions
- OSWorld: 73% through direct environment manipulation
- CAR-bench, FieldWorkArena, Terminal-Bench: 100%
The paper, “How We Broke Top AI Agent Benchmarks,” documents vulnerability patterns systematically. The Berkeley team open-sourced their exploit toolkit as a diagnostic tool for benchmark maintainers, signaling that traditional benchmarks have fundamental measurement problems.
This echoes a broader pattern. Whenever a metric becomes a target, it ceases to be a good metric. Goodhart’s law applies to agent benchmarks just as it does to college admissions tests or corporate KPIs.
Production eval vs offline eval
Most teams discover the gap between benchmark performance and production reliability only after deployment. A 90% GAIA score doesn’t guarantee a 90% success rate in production. Three reasons.
Distribution shift: Benchmark tasks are curated and balanced. Real-world agent queries are noisy, ambiguous, and adversarial. Agents that did well on clean benchmark data see scenarios in production they’ve never encountered.
Environment variability: Benchmark environments are static and deterministic. Production environments have latency, failures, rate limits, and unexpected state changes. An agent that succeeds 95% of the time on a clean WebArena instance might succeed 60% of the time when handling real web services with occasional downtime.
Feedback loops: Benchmarks are evaluated once, offline. In production, failures compound. If an agent makes a mistake, downstream actions amplify the error. Benchmark evals don’t capture this cascade.
Sophisticated teams close the gap with multi-layer evaluation:
- Shadow evaluation: Run the agent on real production queries but don’t act on its outputs. Grade the outputs against human ground truth. This reveals how well the agent generalizes without risk.
- Regression evaluation: After an agent ships, run periodic evals on a fixed set of known tasks. This catches drift: did this week’s model still handle the tasks it handled last week?
- A/B evaluation: Compare agent versions on the same real queries in production. Measure not just task completion but also latency, human intervention rate, and user satisfaction.
Offline benchmarks tell you what your agent could do on curated tasks. Production evals tell you what it actually does in the wild. Most teams have the first and very little of the second, and the bridge between them is where the category is currently weakest.
Common questions
- How do I write evals for my agent?
- Start narrow. Pick 5 to 10 representative tasks your agent should handle. Grade them manually or with a human rubric. Then decide: can this be graded programmatically (function call, exit code)? If yes, automate it. If no, build a lightweight annotation interface and grade manually or with a jury of evaluators. Once you have a working eval, expand to 50 to 100 tasks. Then scale with LLM-as-judge or a pre-built framework like DeepEval or Inspect AI.
- Why do my LLM-as-judge scores swing by 20% on the same agent output?
- Judge nondeterminism. A few causes. First, sampling: if your judge runs at temperature greater than 0, repeated calls produce different scores on identical inputs. Set temperature to 0 and seed the model if your provider supports it. Second, the judge prompt is underspecified: if you ask 'is this answer correct?' without a rubric, the judge hallucinates criteria differently each time. Pin the rubric with worked examples (good answer A scores 5, partial answer B scores 3, wrong answer C scores 1). Third, position bias: when the judge compares two responses, A vs. B, it tends to favor whichever comes first. Randomize the order on each comparison. Fourth, model drift: a managed LLM judge can change behavior week-to-week as the provider updates the model. Pin the model version (for example claude-3-5-sonnet-20241022 rather than claude-3-5-sonnet) in your eval config.
- My agent passes the eval suite but breaks on the first real user query. What's going on?
- Two failure modes that compound. First, your eval set doesn't match the production distribution. Eval tasks tend to be clean and well-specified. Real user queries are messy: misspellings, ambiguous goals, missing context, follow-up questions that reference earlier turns. If your evals are single-turn and your production agent gets multi-turn conversations, the eval was measuring a different thing. Second, your eval set has leaked into the training data or prompt. Some teams iterate on the same eval tasks long enough that the agent (or the prompt) gets overfit to them. Diagnostic: take five real user queries from the last 48 hours, add them to the eval suite, and watch the pass rate drop. The fix is continuous. Pull a fresh sample of real queries each week and add them to the eval set, while keeping a frozen 'golden' subset to detect regressions.
- How do I connect my offline eval scores to what's happening in production?
- Most teams don't, and the gap is the source of a lot of bad surprises. The standard hack: tag each production trace with the model version and prompt version that produced it, then run your eval suite against the same prompt/model combo whenever you ship a change. That gives you correlation, not causation. Enough to catch regressions before users do. The harder version is matching the distribution of production queries (not just rerunning your eval set), which means sampling real queries weekly into your eval suite and watching the pass rate. Teams that do this seriously end up with three concentric eval rings: a frozen golden set (regression detection), a sliding production sample (distribution tracking), and the underlying benchmark (capability ceiling). Few products thread these together cleanly today. Most teams build the connection themselves with scripts and shared dashboards.
Further reading
- UC Berkeley’s “How We Broke Top AI Agent Benchmarks” (rdi.berkeley.edu, April 2026). Comprehensive analysis of benchmark vulnerabilities with open-source exploit toolkit.
- Anthropic’s “Demystifying evals for AI agents”. Practical guidance on eval strategy for multi-step agent tasks.
- Thoughtworks’ “LLM benchmarks, evals and tests: A mental model”. Framework for thinking about the differences between benchmarks, evals, and production tests.
See also: