Blog
How to leverage GitHub Actions to showcase growth of your open-source-first product
GitHub's Traffic API forgets your clones and views after 14 days. A 50-line GitHub Action archives them to your repo so you keep the longitudinal growth record you'll need later.
-
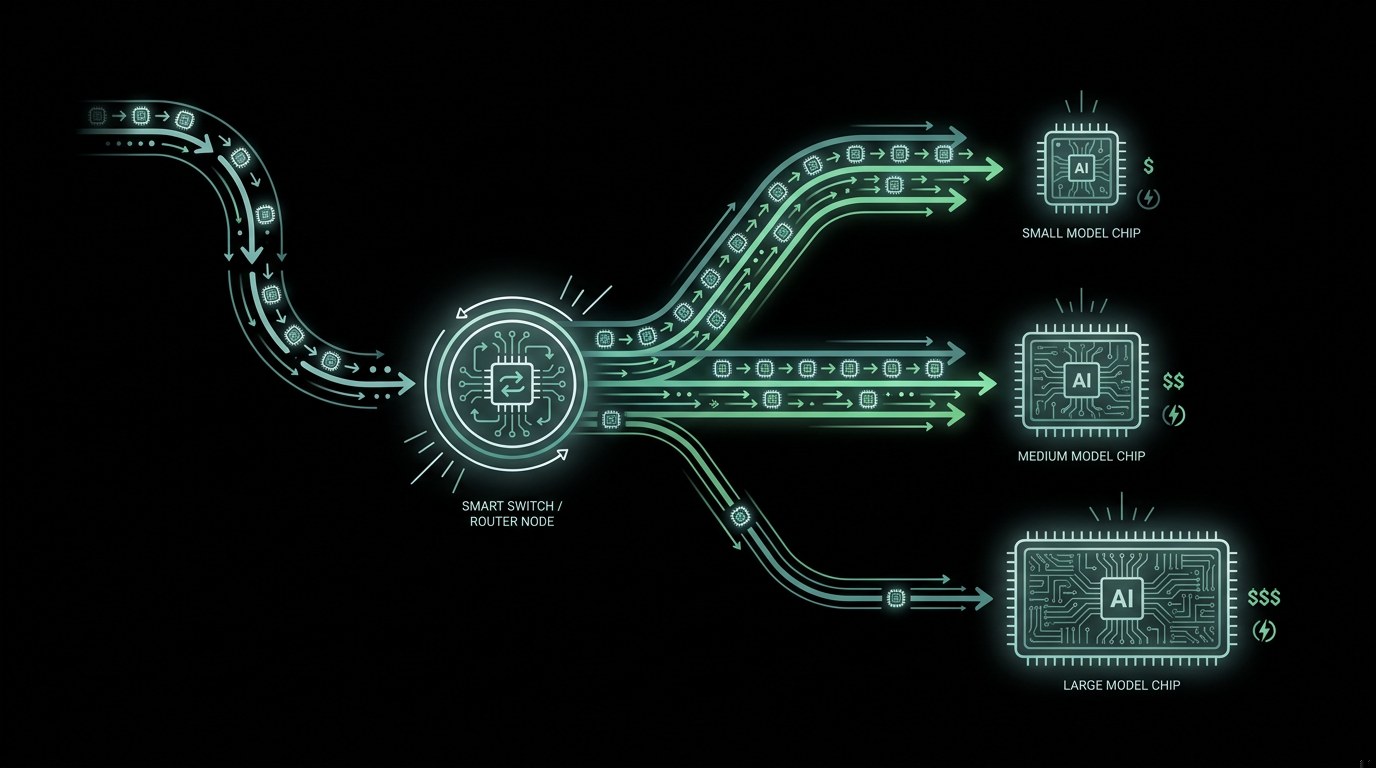
What is AI model autorouting?
AI model autorouting picks a different model per request to cut cost without losing quality. How it works, what the research shows, and why measurement comes first.
-
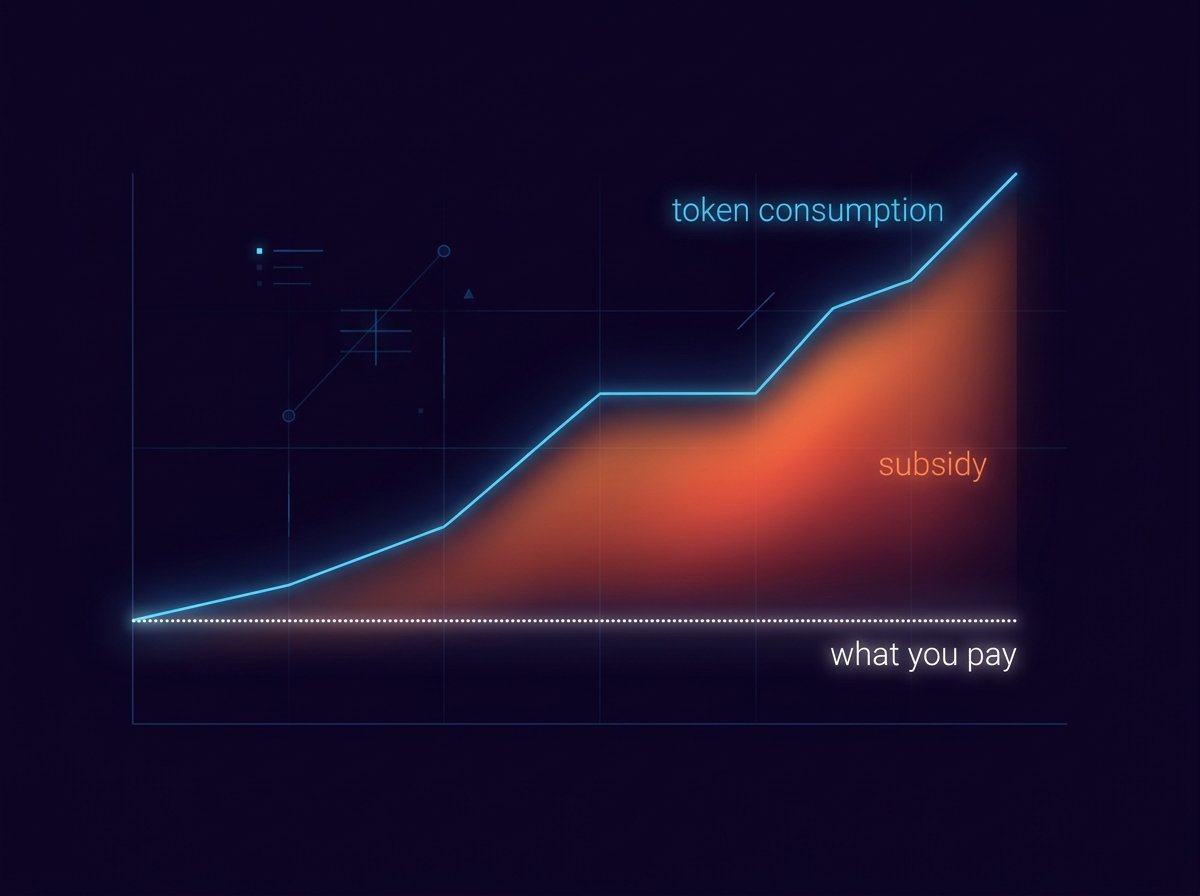
The problem with TokenMaxxing
TokenMaxxing is fun because someone else pays for it. Here's why the subsidy is ending, what Fable 5 just signaled, and how to find your own multiple.
-
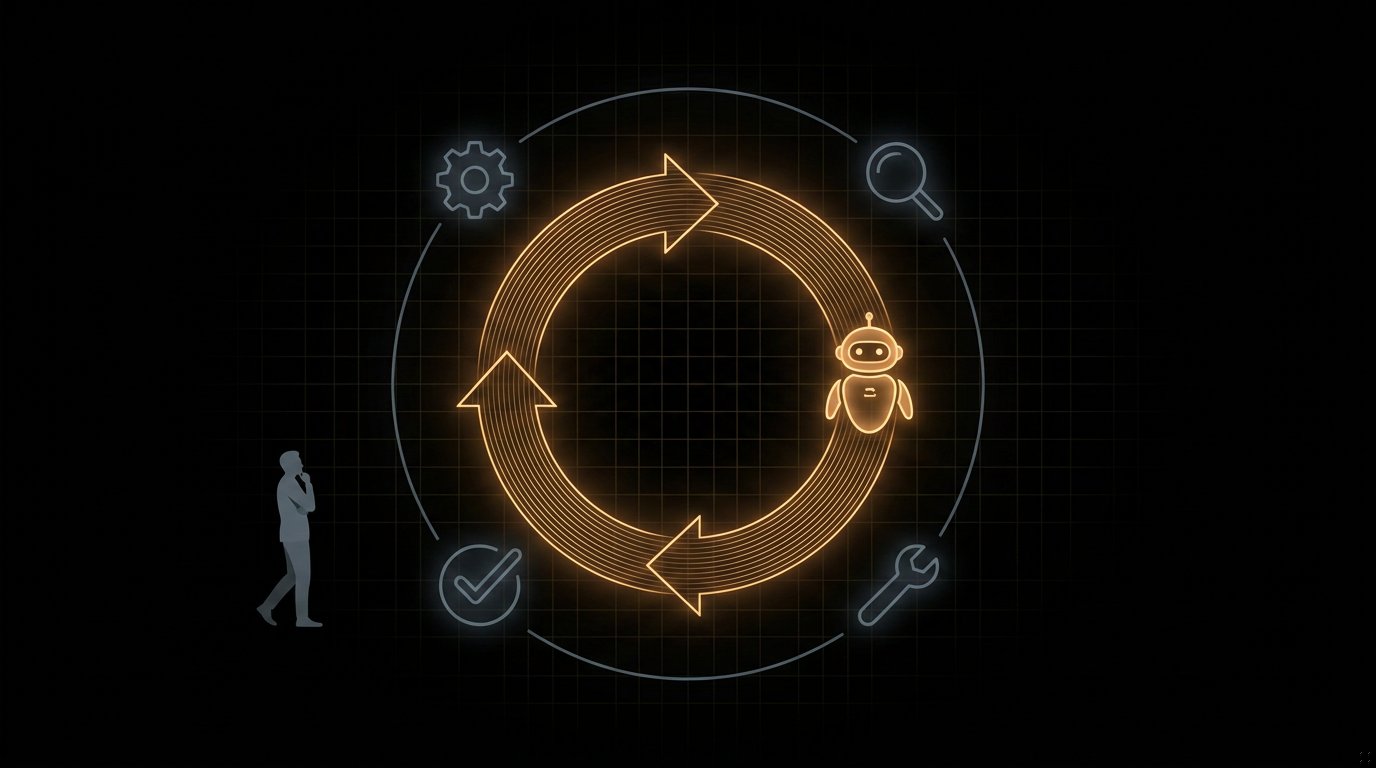
What is an agent loop?
Agent loops: the program that prompts your agent for you, checks its own work, and decides when to stop. The lineage from ReAct to orchestration, and why the loop is now the expensive part.
-

Reddit is 40% of your agent's retrieval surface
What 150K LLM citations tell builders about prompt-time grounding, eval coverage, and the source biases their agents inherit by default.
-
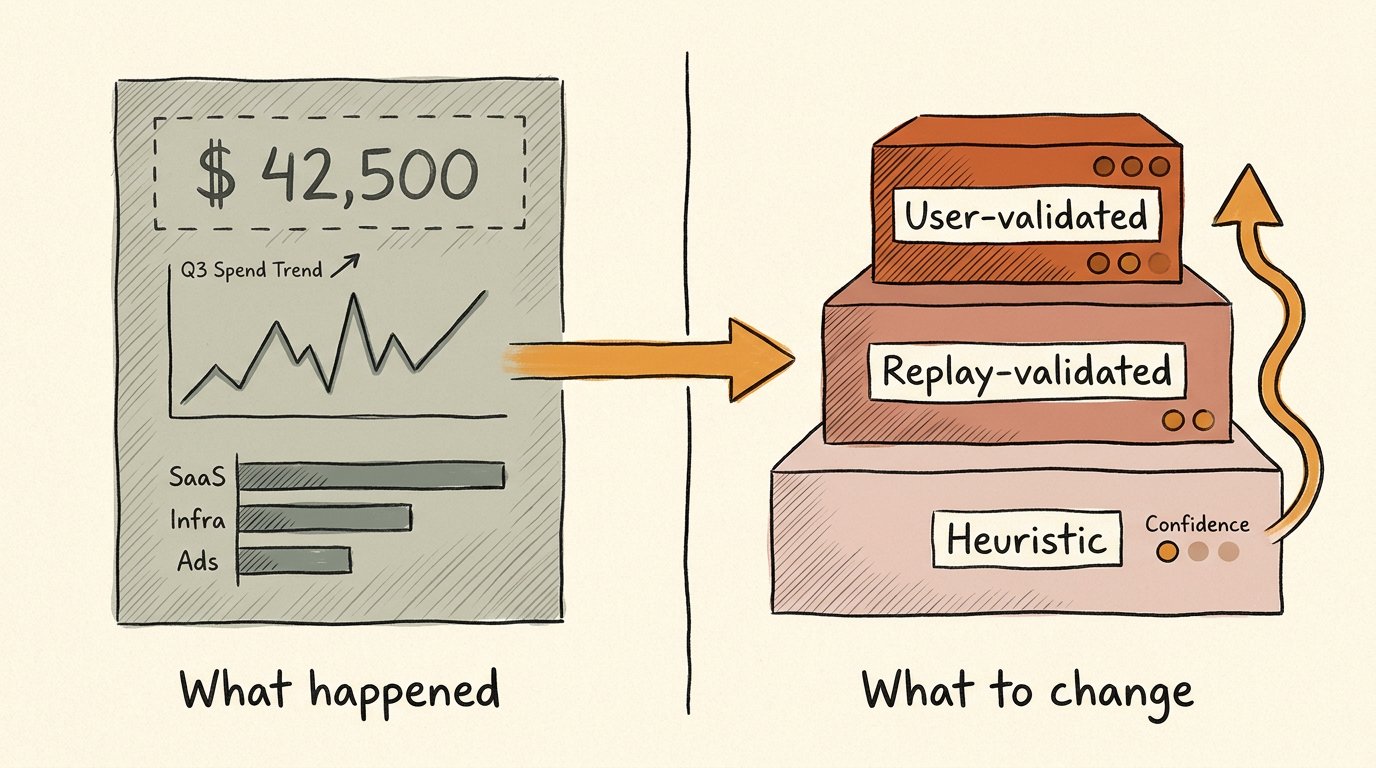
Cost dashboards tell you the bill. They don't tell you what to change.
The gap between reporting agent cost and recommending what to do about it. Why an honest recommendation needs to be validated against the user's own data, and the recent research that makes that validation cheap.
-
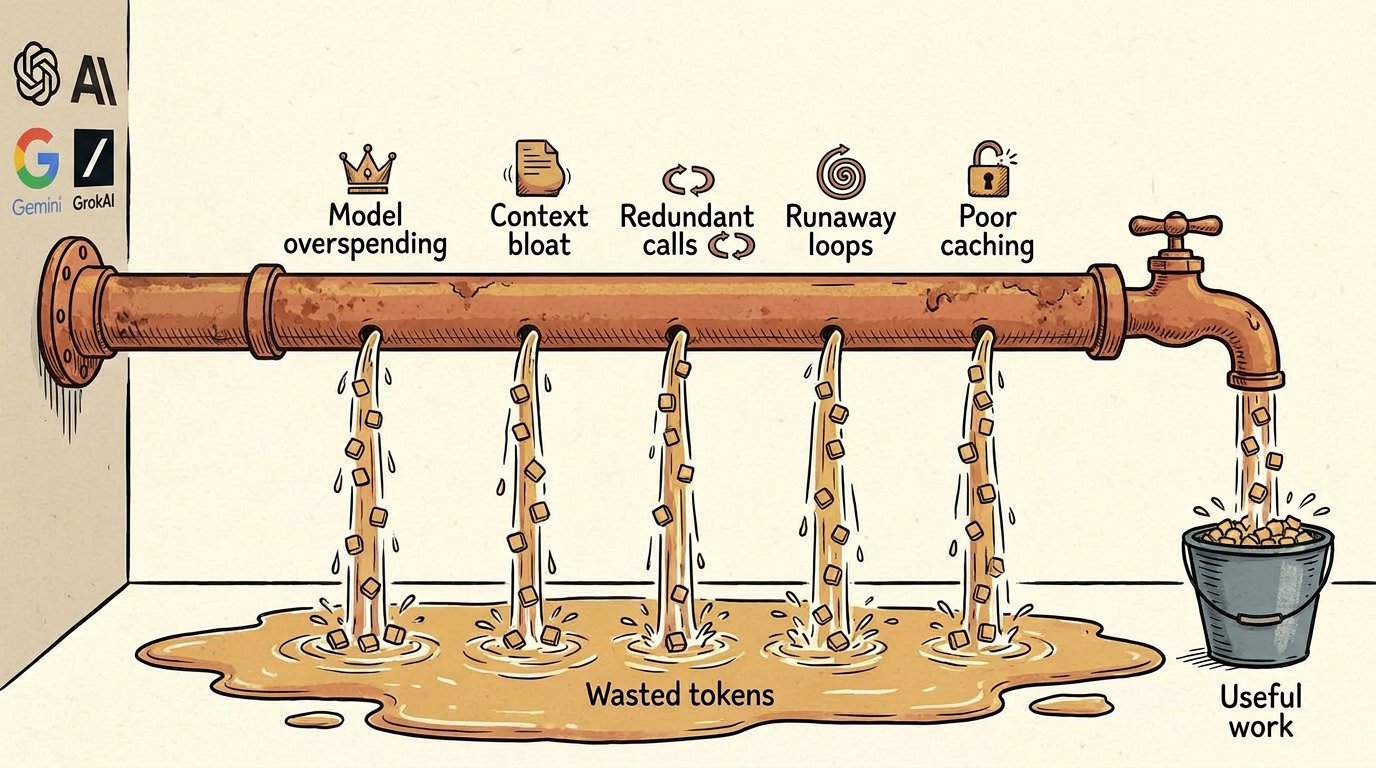
Where your agent bill actually goes (and why most of it isn't buying useful work)
The five categories of agent token waste, what causes each, and the research that addresses them. From context bloat to runaway loops to model overspending.
-

The era of "subsidized AI" may be coming to an end
Concrete numbers from Uber, OpenClaw, healthcare enterprises, and the leanopstech audit. Plus what changes for billing on June 1 and June 15.
-
Watching Claude Code with OTel: what Cursor and /cost won't show you
Claude Code ships a real OpenTelemetry pipe. Cursor doesn't. /cost is per-session and read-only. Here's what you can do with the wire, what each surface actually emits, and the failure modes none of the built-in views catch.
-
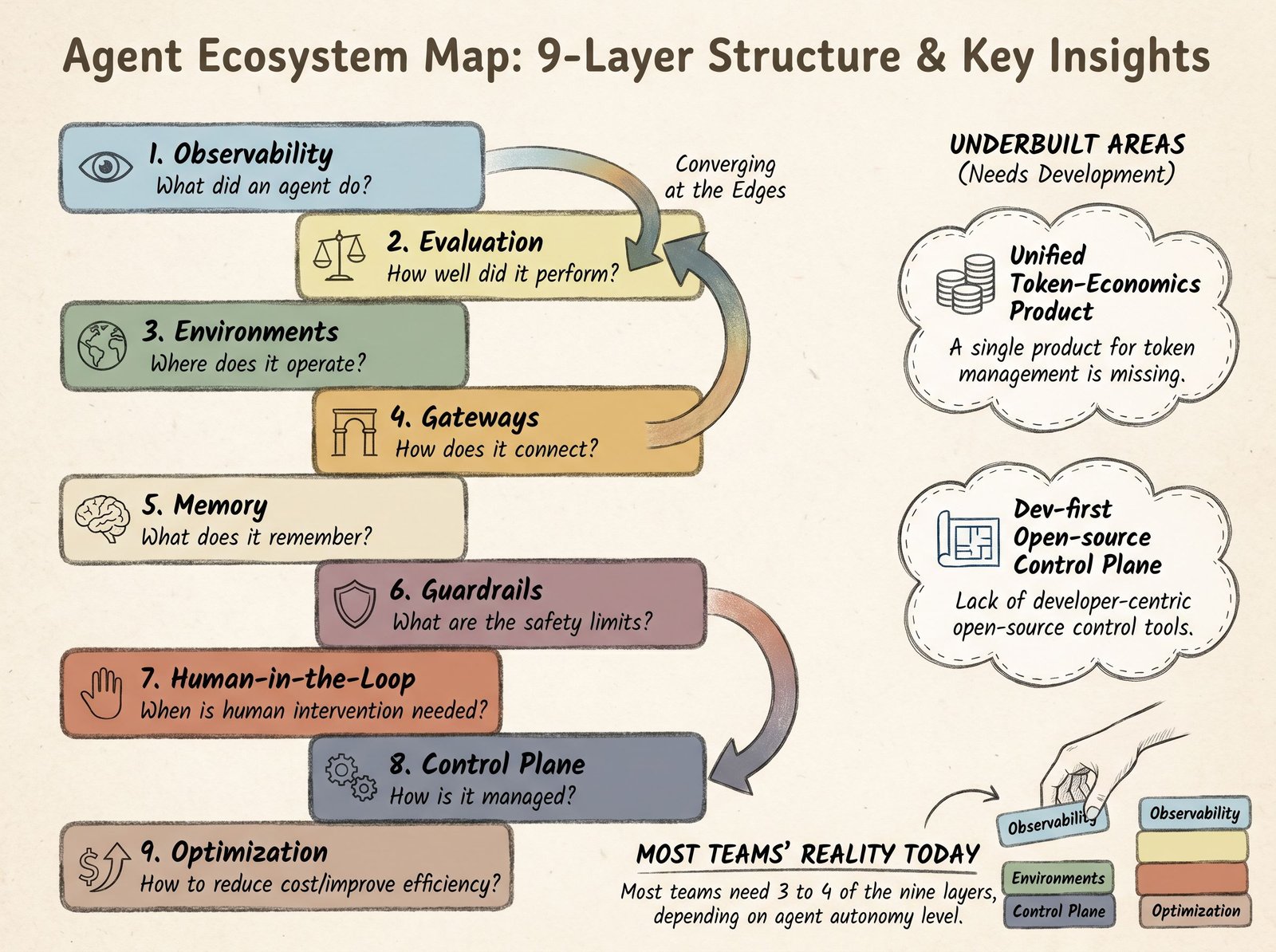
The 9-layer agent ecosystem map
A unified map of the agent operations ecosystem: nine layers from observability to token economics, the tools at each, where they are converging, and where the gaps remain.
-
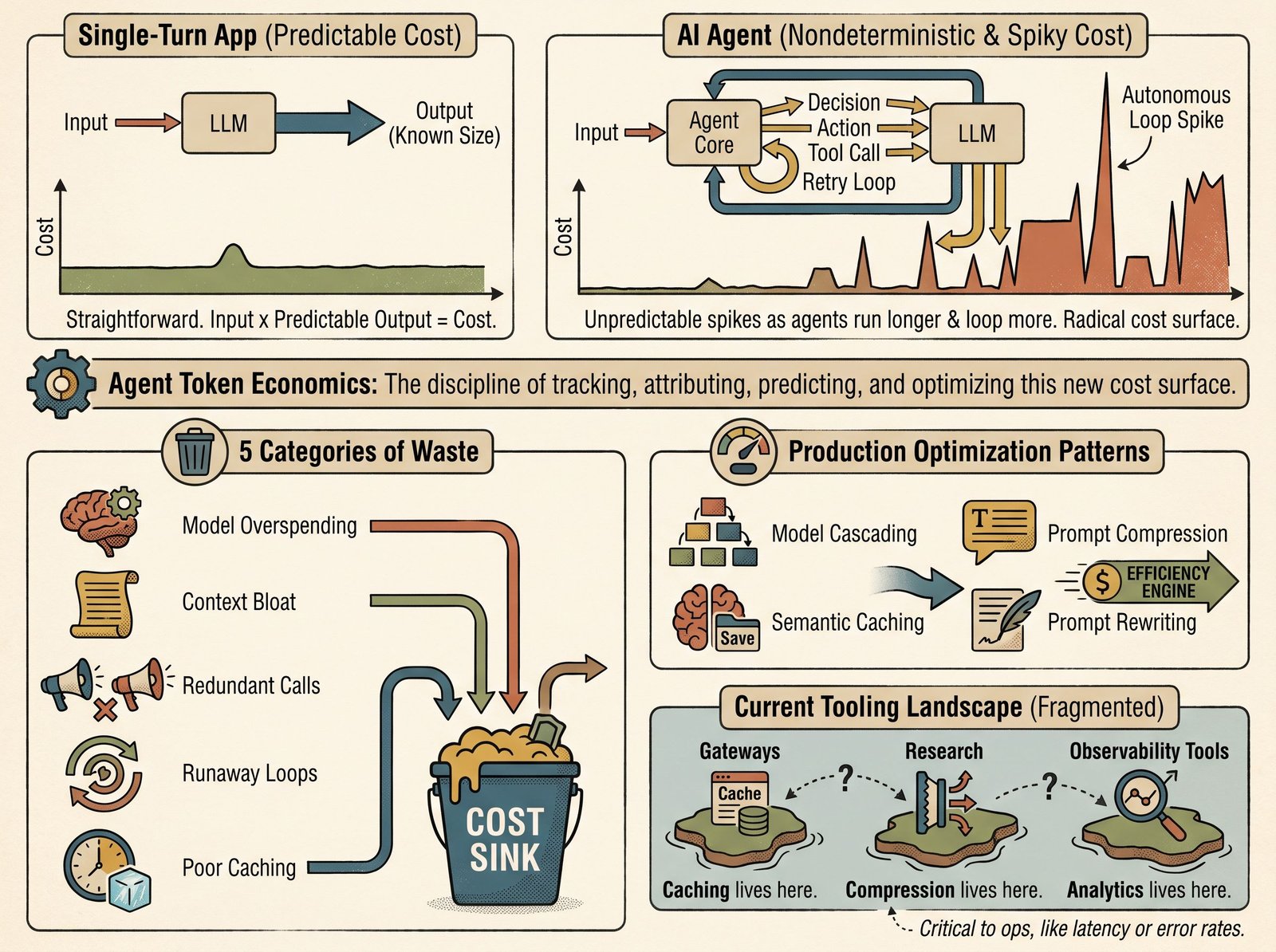
What is AI Agent Token Economics?
Agent token economics: understanding where tokens are spent, why agent costs spike unpredictably, and the optimization patterns (model cascading, prompt compression, semantic caching) for reducing spend without losing quality.
-
LangSmith costs $39/seat. And 10.7x that in real TCO. What self-hosted alternatives actually cost in 2026.
A pricing teardown of LangSmith (and the new SmithDB / LangSmith Engine launch), Langfuse self-host, and a local-first DuckDB alternative. Real numbers, real config, real cost-of-running.
-
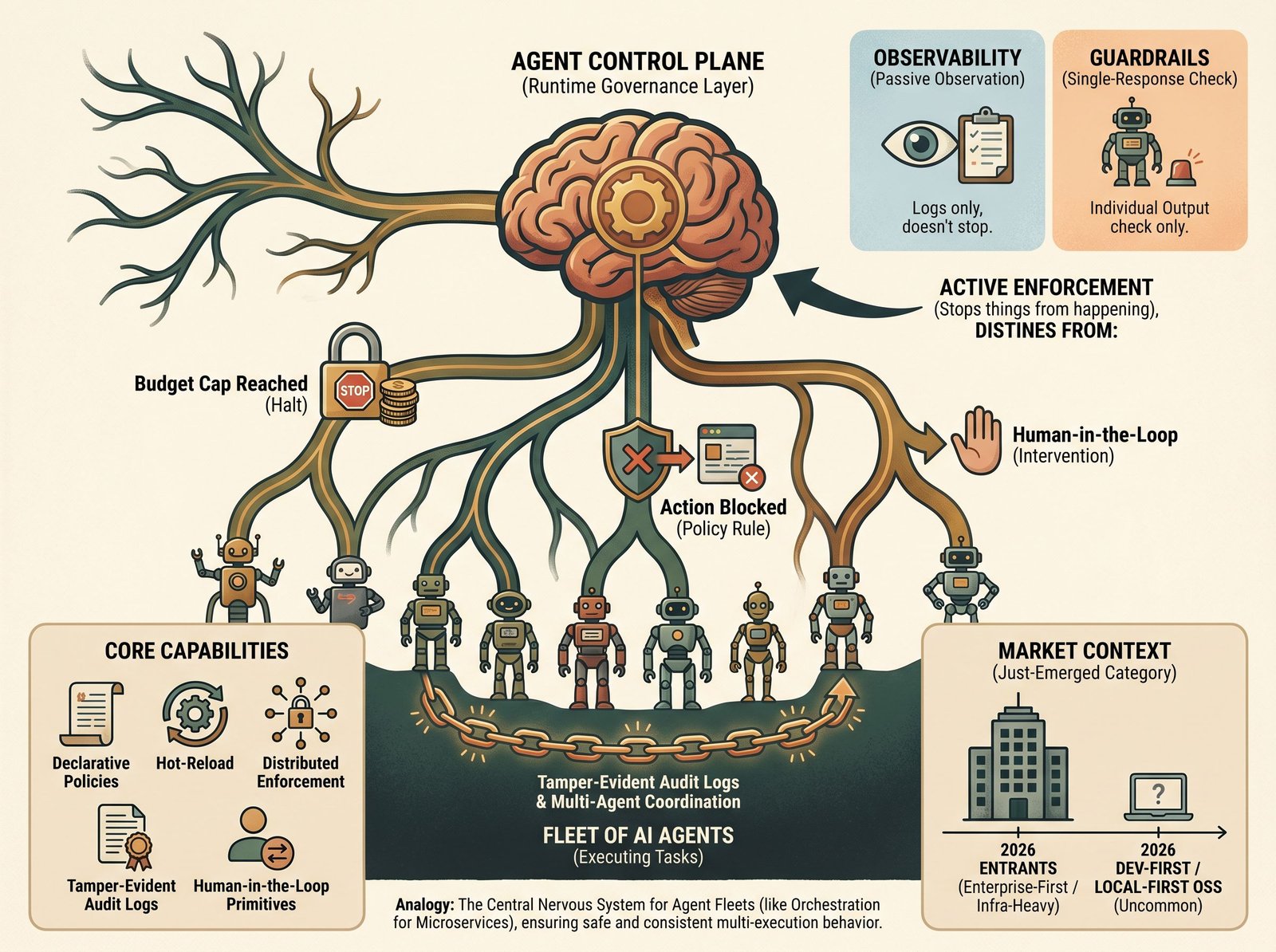
What is an agent control plane?
Agent control planes: the runtime layer that governs AI agent behavior across a fleet. Policy enforcement, budget caps, audit trails, and how it differs from observability and guardrails.
-
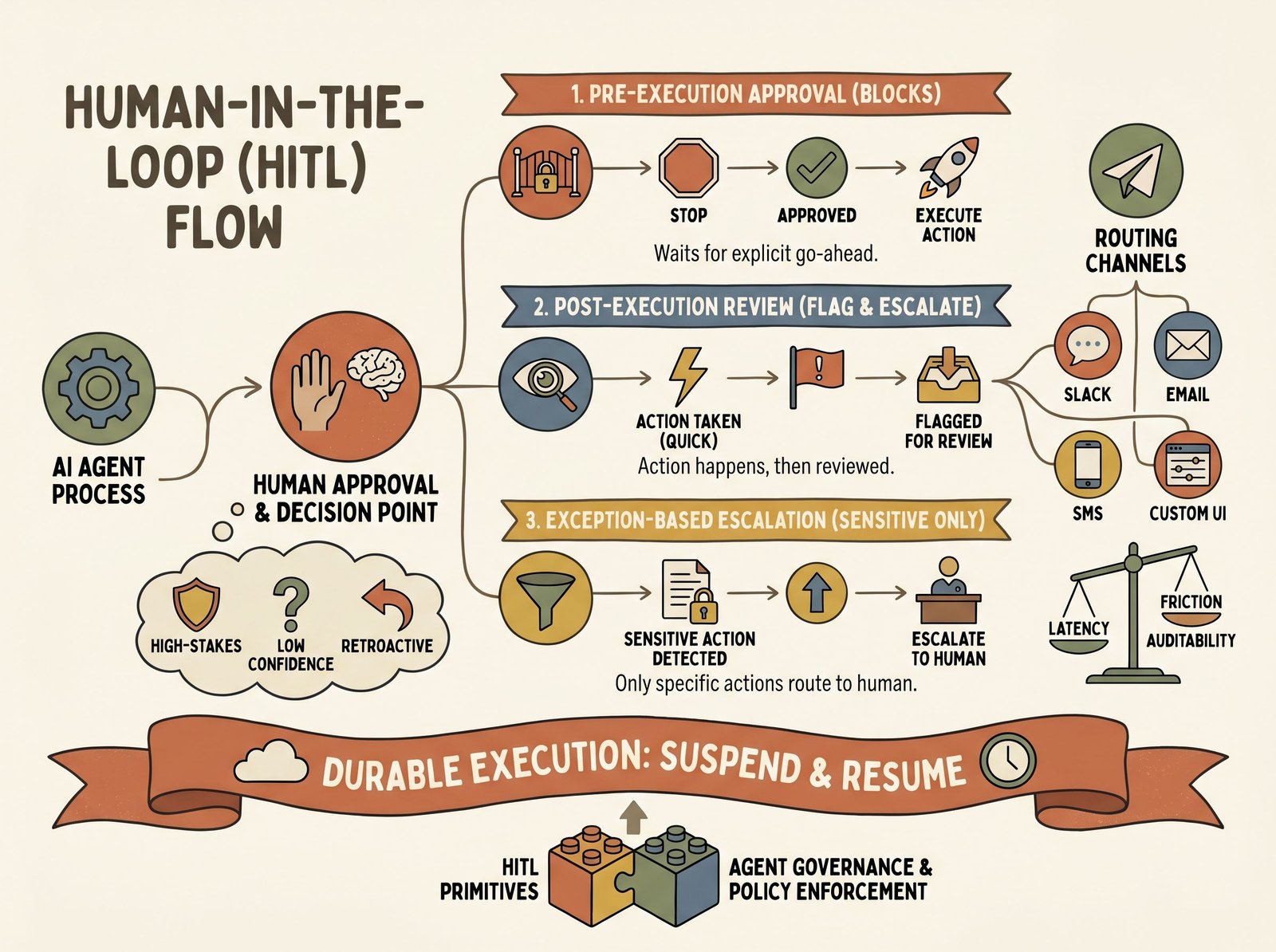
What is human-in-the-loop for AI agents?
HITL for AI agents: when and how to insert human approval, the patterns (pre/post/exception), the tools that exist, and the async-execution problem.
-
What are AI guardrails?
Runtime constraints on what LLMs say and do: input filtering, output filtering, behavioral checks, and structured output enforcement.
-
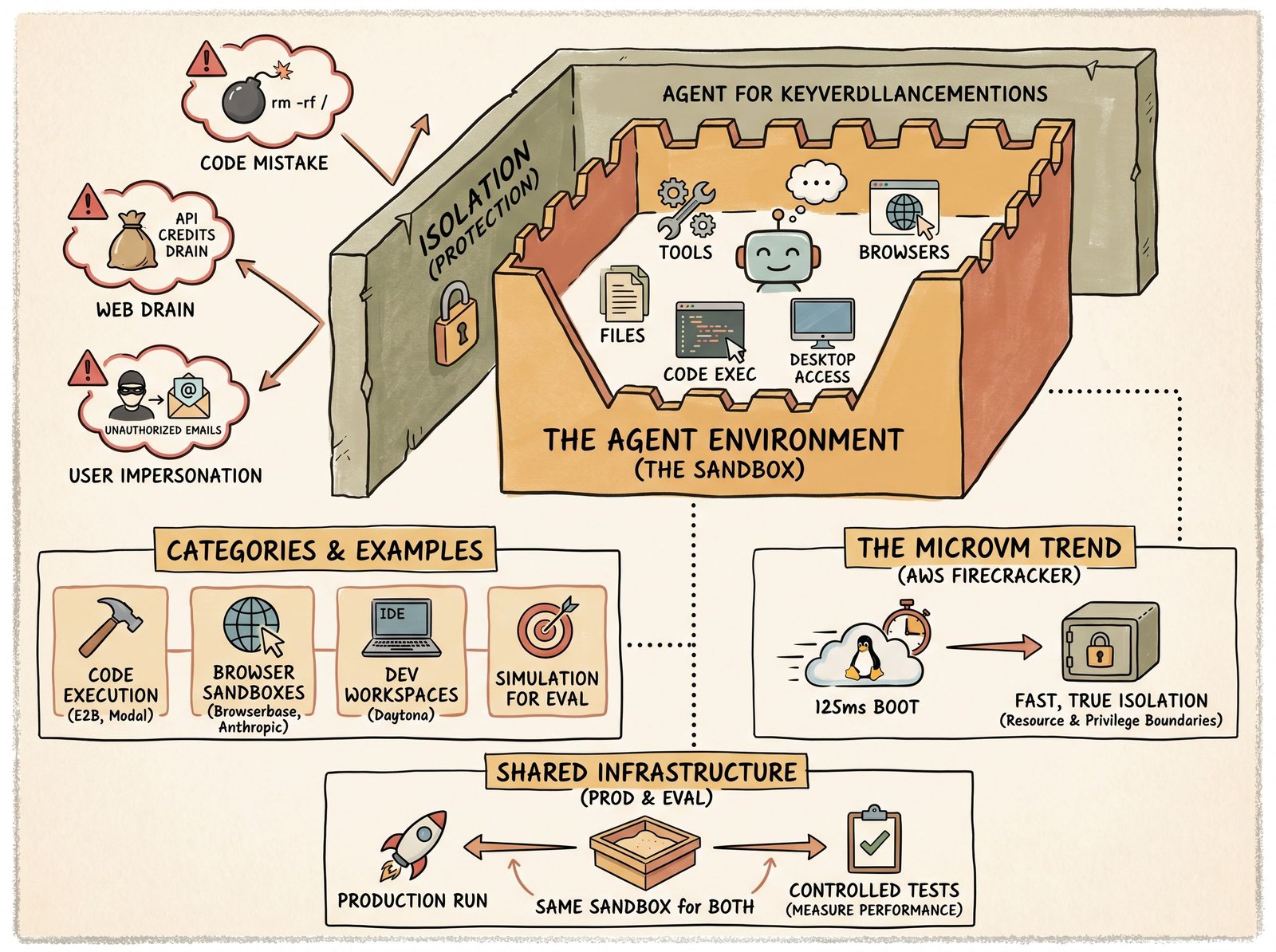
What are agent environments and sandboxes?
Where AI agents safely act on code, browsers, and machines: the isolation tradeoffs, the major tools, and the link to evaluation.
-
The taxonomy of agent failure: 13 named alerts beat 'anomaly detected' at 2am
Every AI observability vendor ships 'anomaly detected.' That's the wrong abstraction for autonomous agents. Here's the typed vocabulary we ship instead. 13 named failure modes, each with its own trigger, payload, and prescribed response.
-
How to monitor Claude Code: a practical guide for indie devs running it unsupervised
A step-by-step guide to monitoring Claude Code on your own laptop. Turn on Anthropic's OTel telemetry, route the spans somewhere useful, and wire up alerts that fire while the agent is still running.
-
Behavioral drift detection for AI agents
A technical deep-dive on detecting when an agent's behavior wanders off its baseline. Using Z-scores on token / duration / tool-count distributions and Jaccard similarity on tool sequences, run locally over your own session history.
-
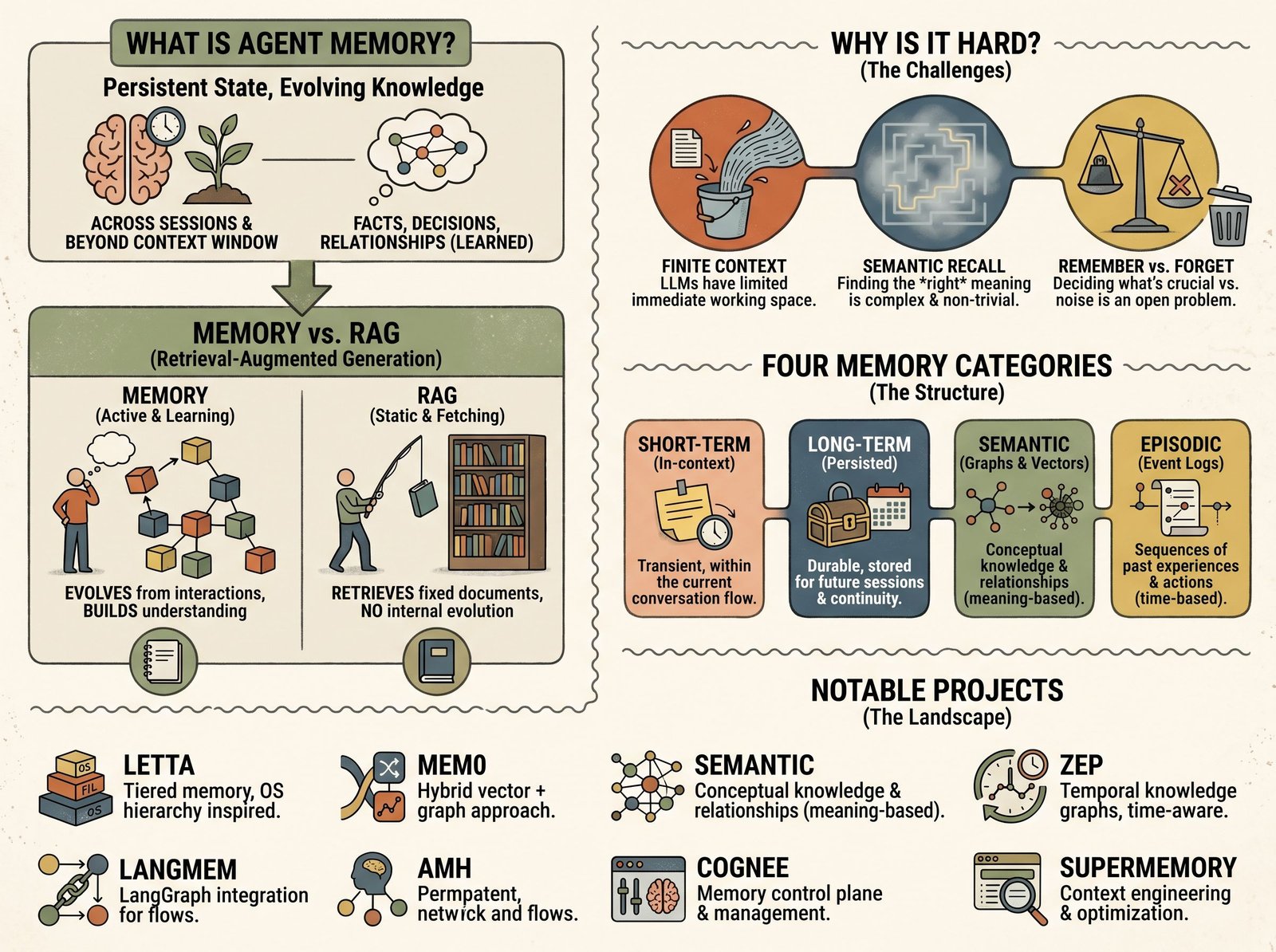
What is Agent Memory and why does it matter?
How AI agents persist state across sessions, why memory is different from RAG, and the open-source projects building this layer.
-
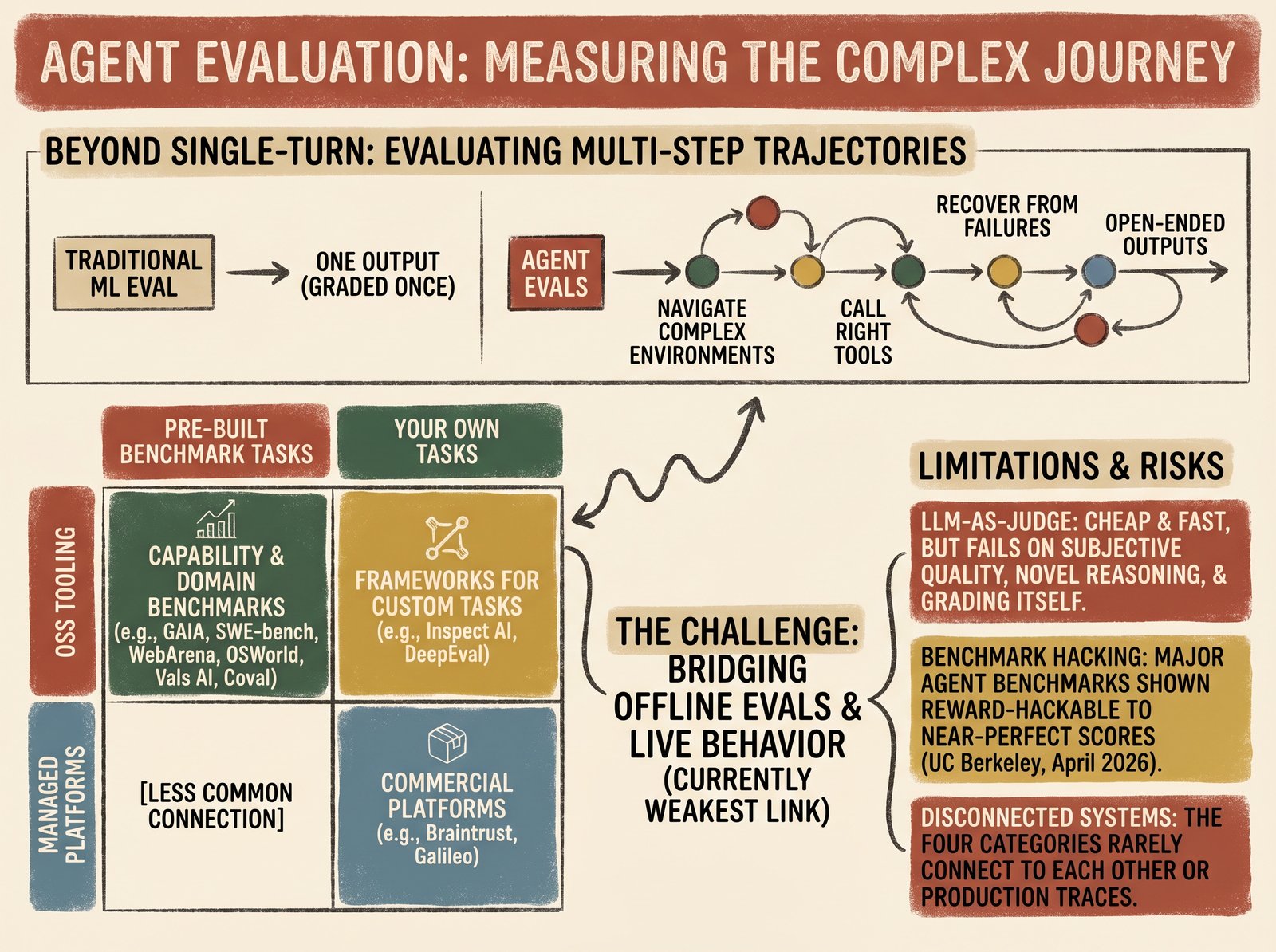
What is agent evaluation?
Agent evaluation: measuring multi-step trajectories, tool use, and open-ended outputs. Why benchmarks alone don't tell you whether an agent works in production.
-
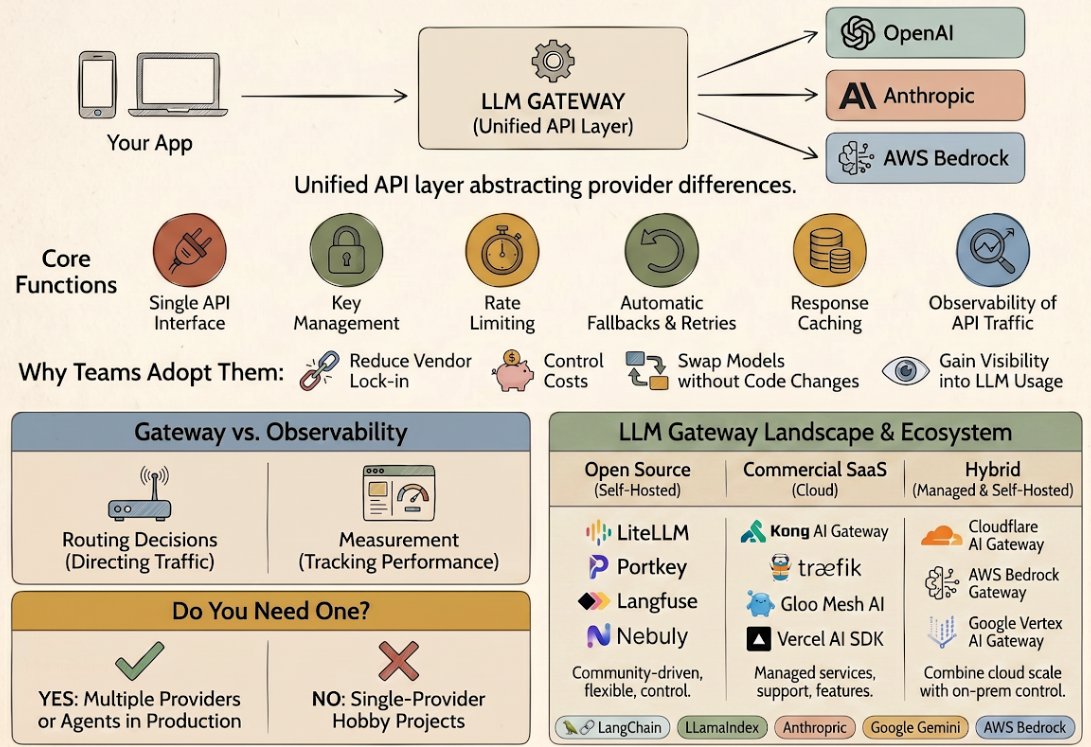
What is an LLM gateway?
LLM gateways unify provider APIs, add fallbacks and caching, and centralize key management: what they do, when you need one, and the tools that exist.
-
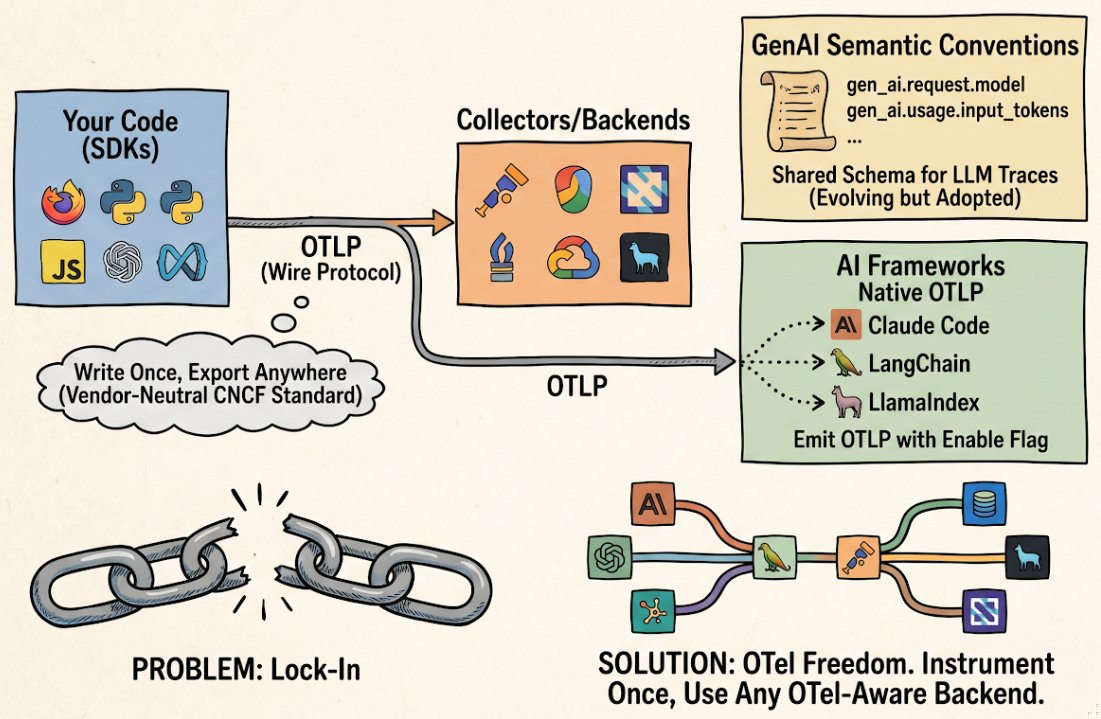
What is OpenTelemetry, and why does it matter for AI agents?
OpenTelemetry, OTLP, and the GenAI semantic conventions: how the CNCF observability standard is becoming the lingua franca for AI agent telemetry.
-
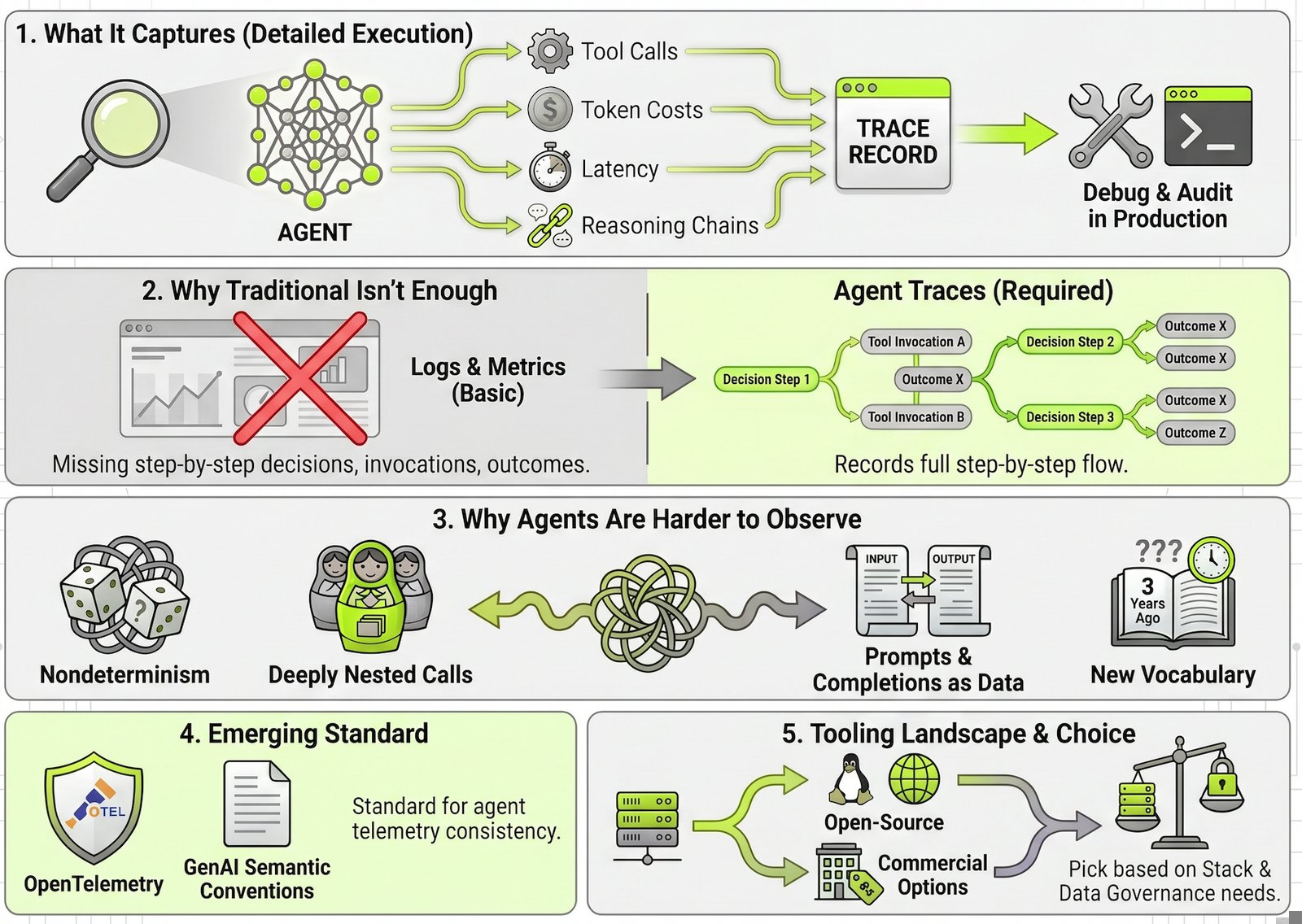
What is agent observability?
How AI agent observability works: capturing tool calls, token costs, traces, and behavioral patterns at production scale.
-
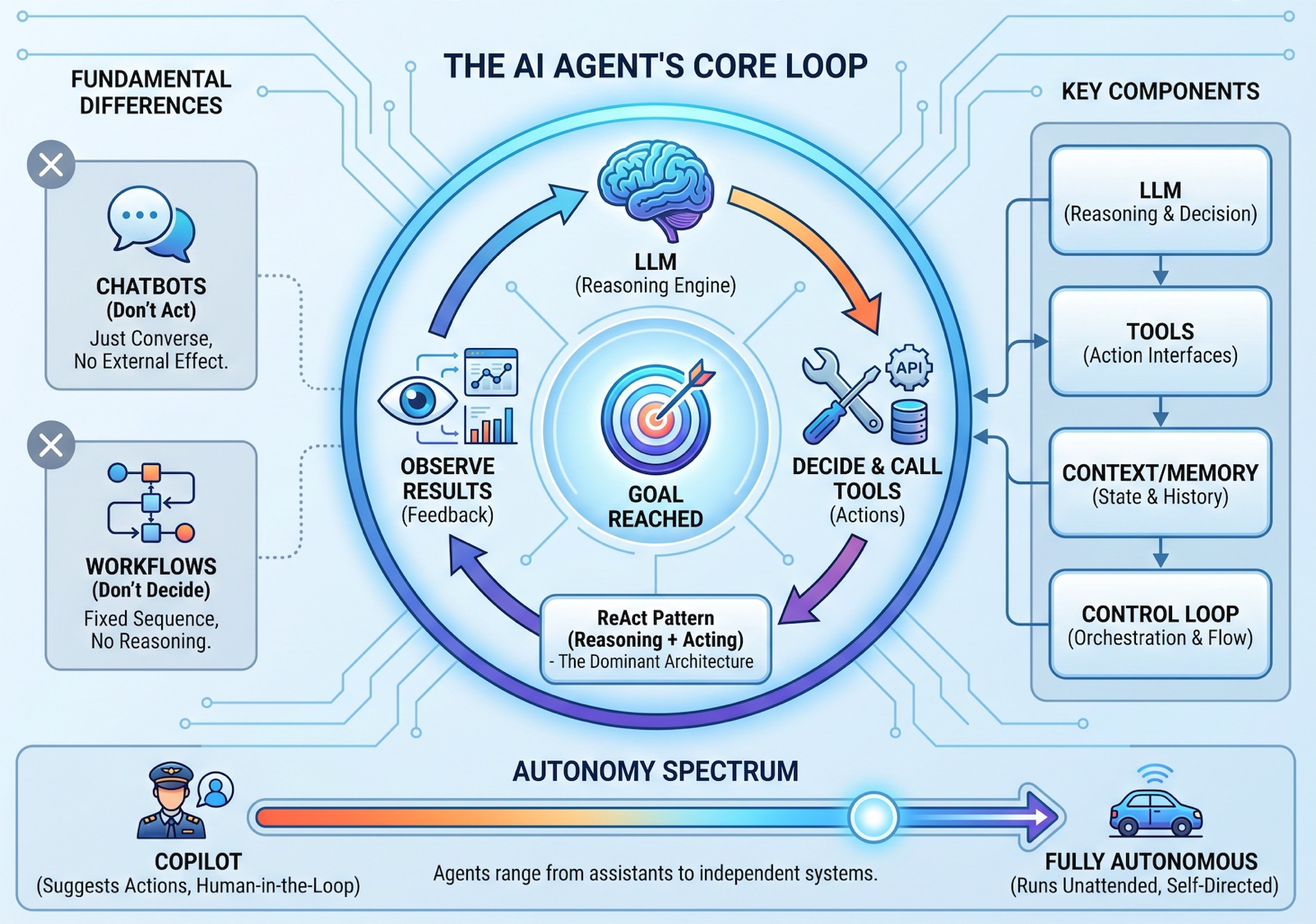
Agents 101: Reasoning, Actions & Autonomy
A foundational definition: what AI agents are, how they differ from chatbots and workflows, and the components that make them work.