What is AI Agent Token Economics?
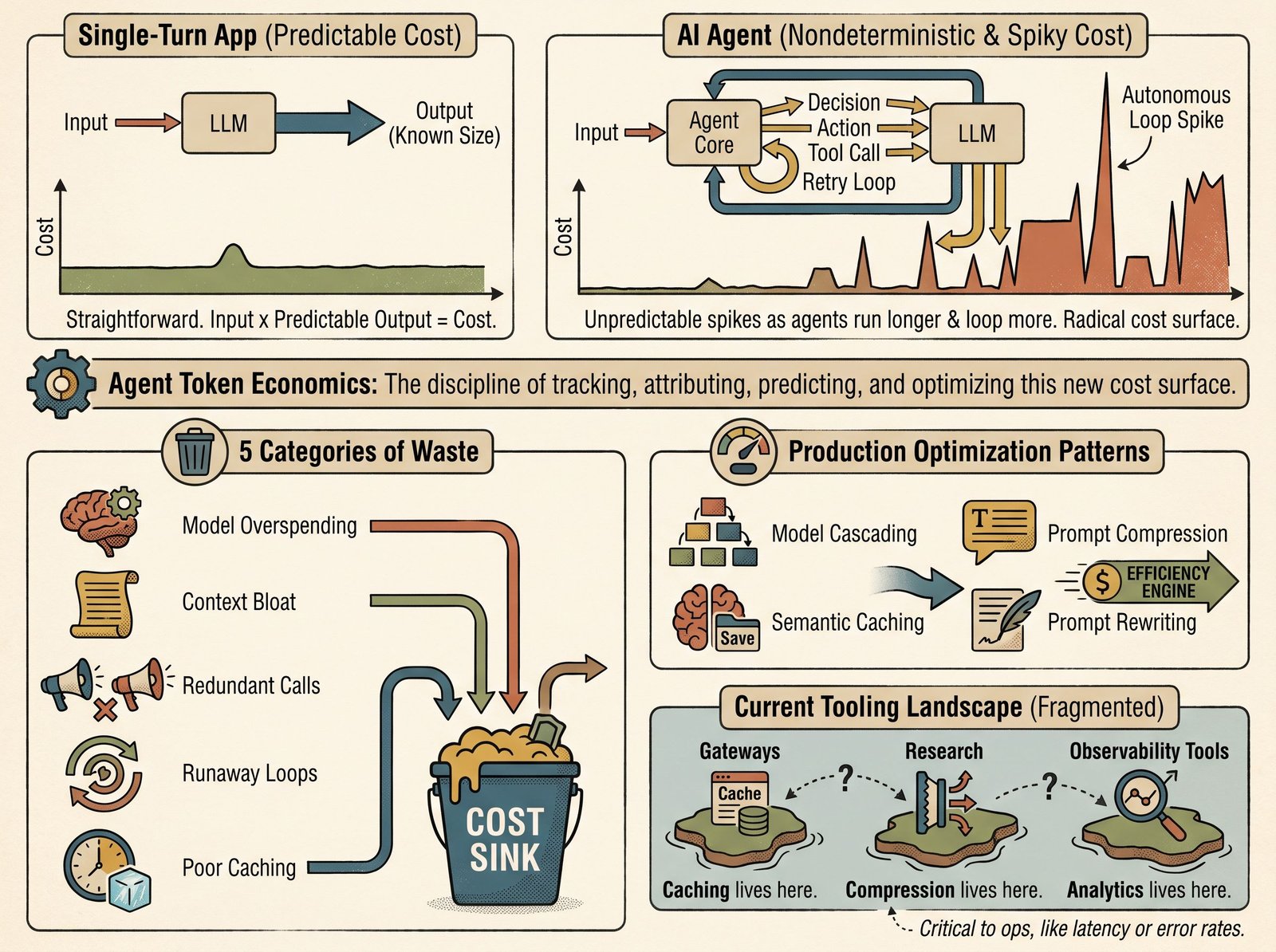
For single-turn applications (a chat message, a search query), token economics is straightforward: you know the input size, predict the output, and multiply. For agents (systems that make decisions, take actions, loop, and call tools for hours or days), the cost surface is radically different. A single agent session can burn through dollars in minutes if it gets stuck in a retry loop or if its context window bloats with intermediate results. Understanding and managing this cost is becoming as critical to agent operations as latency or error rates.
Why it matters more than it used to
Agents are now autonomous enough to run unattended for hours or days. They make decisions, call external tools, refine strategies, and retry failed steps, all without human intervention between actions.
This changes the cost calculus. In a chat application, you see the bill at the end of a session. With agents, you’re managing a fleet of long-running processes, each consuming tokens silently until an error, timeout, or budget limit halts it. A chatbot that costs $0.10 per session becomes an agent that costs $50 when it loops. A system prompt that was acceptable at 2,000 tokens becomes unsustainable when it multiplies across 100 agent runs per day.
This is why token economics now matters: costs scale with agent autonomy, and you need visibility into where the money is going and why it spikes.
Categories of waste
Most token waste falls into five patterns:
Model overspending. Using a larger, more expensive model than a task needs. Claude 3.5 Haiku is sufficient for classification or routing. A team builds everything with Opus anyway and pays 5–10x more. The overspend is transparent and easy to fix once identified.
Context bloat. System prompts, tool definitions, and few-shot examples grow over time without governance. A system prompt that started at 500 tokens balloons to 5,000 as teams add safety guardrails, prompt injection mitigations, and edge-case handling. Each agent call pays the full cost of the bloated prompt.
Redundant calls. An agent asks the same question twice in five minutes. A tool returns a result, the agent processes it, then asks a follow-up that could have been predicted. Or an agent calls the same API twice to fetch data it already retrieved. These trace to poor memory management or missing deduplication logic.
Runaway loops. An agent fails to complete a task, retries, fails again, and keeps looping until a budget cap or timeout stops it. A tool might return malformed output, or a dependency might be down. Without proper loop detection, the agent burns tokens on repeated failed attempts. A single stuck agent can consume a monthly budget in hours.
Poor caching. Results that should be cached are recomputed. An agent fetches user data in step 1, processes it in step 2, then fetches it again in step 3 because the data wasn’t cached. Or a system prompt or tool definition is sent with every request instead of being cached server-side.
Optimization patterns
The agent ecosystem has converged on several optimization patterns, each addressing one or more categories of waste:
Model cascading
Concept: Try a cheaper model first. Route to a more capable (expensive) model only when the cheaper one fails or returns low-confidence results.
Why it works: Most queries don’t require GPT-4 or Claude Opus. Haiku or a smaller open model can handle 70–80% of requests. Only the hard cases escalate.
Evidence: Chen, Zaharia, and Zou’s FrugalGPT framework (Stanford, 2023) demonstrates that model cascading can match GPT-4 performance while reducing costs by up to 98% on some datasets. The framework learns which combinations of models to use for different queries, and code is available on GitHub.
Gotchas: Cascading introduces latency (you try the cheap model first, it fails, then you retry with the expensive one) and complexity (you need metrics to decide when to escalate). It works best when cheap models are very fast and have clear failure signals, such as low confidence scores.
Prompt compression
Concept: Remove redundant or less-important tokens from your system prompt, few-shot examples, or input context without losing semantic meaning.
Why it works: Prompts contain boilerplate, repetition, and verbose explanations that don’t help the model. Compression can reduce token count by 30–50% without measurable quality loss.
Evidence: LLMLingua (Microsoft, EMNLP 2023) uses a small language model to identify and remove unimportant tokens from prompts. Testing on four datasets (GSM8K, BBH, ShareGPT, Arxiv) showed up to 20x compression while preserving quality on in-context learning and reasoning tasks. The tool is integrated into LangChain and LlamaIndex.
Gotchas: Compression is not tokenization. Removing 500 tokens via compression might only save 10 tokens in actual API cost if those tokens are already within your model’s “thinking” budget. Compression also requires tuning. Compress too aggressively and quality drops. Most teams see 20–40% cost savings in practice, not 20x.
Semantic caching
Concept: Cache LLM responses based on semantic similarity, not exact string match. If a user asks “What is the weather in San Francisco?” and later asks “What’s the weather in SF?”, the cache hits even though the strings differ.
Why it works: Exact-match caching (Redis, memcache) misses many near-identical queries. Semantic caching converts queries to embeddings, searches for similar cached prompts, and returns the cached response if the similarity score is high enough.
Example tool: GPTCache (Zilliz) provides a modular semantic cache that integrates with LangChain and LlamaIndex. It supports various vector stores (Milvus, Zilliz Cloud, FAISS) and reduces latency and cost by caching semantically similar queries.
Gotchas: Semantic caching works best for repeated queries (customer support, FAQ bots). It adds latency (embedding plus vector search) and complexity (tuning similarity thresholds). For novel, one-off queries, the overhead outweighs the benefit.
Prompt rewriting from production data
Concept: Analyze failed or low-quality agent runs in production, extract the patterns that caused issues, and rewrite system prompts or few-shot examples to address those patterns.
Why it works: Prompts written in a vacuum miss critical edge cases. Production data reveals what breaks, and targeted rewrites reduce retry rates and downstream costs.
Challenge: This requires observability (you need to capture and analyze agent runs) and discipline (you need a process for deciding when to update prompts). Most teams don’t have this yet.
Batch optimization and prompt caching
Concept: Batch multiple requests together to amortize overhead. Cache large, static portions of prompts (system instructions, tool definitions) server-side so they’re reused across requests.
Anthropic prompt caching: Designate parts of your prompt with a cache_control parameter. Cached content is stored on Anthropic’s servers and reused for up to 5 minutes (standard) or 60 minutes (extended). Cached tokens cost 10% of the input token cost; cache writes cost 25% more. This is most effective when you have large static sections (for example, a 4,000-token system prompt used in 100+ calls per day).
OpenAI prompt caching: Works automatically for prompts 1,024 tokens and longer. Caching can reduce latency by up to 80% and input token costs by up to 90% when there’s substantial overlap between requests. No code changes required; works with gpt-4o and newer.
Both approaches work best with repetitive, static content (tool definitions, safety guidelines) and high query volume.
Current state of the ecosystem
Token economics tooling is fragmented. Caching lives in API gateways (Anthropic, OpenAI). Prompt compression lives mostly in research (LLMLingua) with limited production adoption. Model cascading is still largely a research artifact (FrugalGPT) rather than a standard pattern in production AI stacks. Cost analytics exist in observability tools, rarely with actionable recommendations (“Your system prompt is 30% larger than peers; here’s how to trim it”).
Most teams optimize token economics reactively: they see a spike in costs, audit their logs, find a runaway loop or bloated prompt, and fix it. Proactive optimization (compressing prompts upfront, cascading models by default, precomputing cached responses) is still rare.
The gap is not in algorithms. It’s in integration, observability, and workflow. Token economics will become a standard part of agent operations when cost insights are wired directly into CI/CD, observability dashboards, and model selection logic.
Common questions
- How do I track token spend per agent?
- Log token counts (input_tokens, output_tokens, cache_creation_tokens, cache_read_tokens) for every API call, then aggregate by agent ID, task, or model. Most observability platforms provide this out of the box. The harder part is attributing costs across distributed agent steps. If Agent A calls Agent B, who pays for B's tokens? That requires explicit tagging in your logging layer.
- My Claude Code bill tripled this month and I can't tell why. Where do I look?
- Walk the five waste categories in order of likelihood. First, model drift: did someone switch a sub-agent or a default from Haiku or Sonnet to Opus? Check the model field on your highest-volume call type. Second, context bloat: diff your current system prompt against last month's. A prompt that grew 40% multiplies across every call. Third, loop incidents: sort sessions by cost descending. If the top 1% of sessions account for 30% of spend, you have runaway loops, not a broad increase. Fourth, cache misses: check your prompt-cache hit rate, and if it dropped, something is busting the cache (a timestamp in the system prompt, a reordered tool list). Fifth, volume: maybe you're simply running more agents. The fastest read is the cost-per-session distribution. A fat tail means loops. A shifted median means bloat or model choice.
- Does prompt compression actually work in production?
- Yes, with caveats. LLMLingua and similar tools can reduce token count by 20–40% in many cases. The tradeoff is inference latency (compression itself costs time and compute) and occasional quality loss on very tight reasoning tasks. It works best for large system prompts or many-shot examples where redundancy is high.
- How much can I realistically save?
- It depends on your waste profile. Teams with severe context bloat or frequent redundant calls can save 50–70%. Teams that already optimize carefully might save 10–20%. Model cascading is the largest lever if you're currently using Opus for all queries (3–10x cost reduction). Semantic caching helps if you have high query repetition; it's less useful for novel, one-off requests.
- I turned on prompt caching and my bill went up. How?
- Prompt caching has a write premium. On Anthropic's API, a cache write costs 25% more than a normal input token, and a cache read costs 10% of one. Caching only pays off if reads substantially outnumber writes. If your prompt changes slightly on every call (a timestamp, a per-user detail, a tool list in non-deterministic order), every call is a cache miss that triggers a fresh write, and you pay the 25% premium with none of the 10% read savings. Two fixes. Put the volatile content at the end of the prompt, after the cached static block, so the static prefix stays identical and cacheable. And check your cache hit rate directly: if it isn't well above 50%, caching is costing you, not saving you. Caching rewards large static prefixes reused many times within the cache window. It punishes prompts that look different on every call.
- Should I build or buy token optimization tooling?
- Model cascading and prompt caching can be implemented in-house; they're straightforward logic. Prompt compression and semantic caching are more complex and better sourced from libraries (LLMLingua, GPTCache). Cost attribution and observability require careful logging. Consider integrating with existing observability platforms rather than building from scratch.