Cost dashboards tell you the bill. They don't tell you what to change.
Cost dashboards have proliferated alongside the agent ecosystem. Command-line utilities parse per-session JSONL on a laptop. Open-source observability platforms store agent traces with cost columns. Several agent frameworks ship their own usage views. The provider consoles (Anthropic, OpenAI, Google) all improved their cost views meaningfully in the past year. The data layer is no longer the missing piece.
What’s missing is the next step. A bill is a fact. A recommendation is an action. The gap between knowing your bill and knowing what specifically to change about it is where most of the actual value sits, and it is the part of the cost discipline category that nobody has shipped credibly.
What cost dashboards do
They answer one question well: how much did I spend, broken down by some axis (model, time period, user, project). That answer is useful. It catches the gross surprises: a forgotten background agent, a misconfigured webhook, a single developer who racked up a four-figure weekend bill on an autonomous refactoring session (as discussed in the previous post).
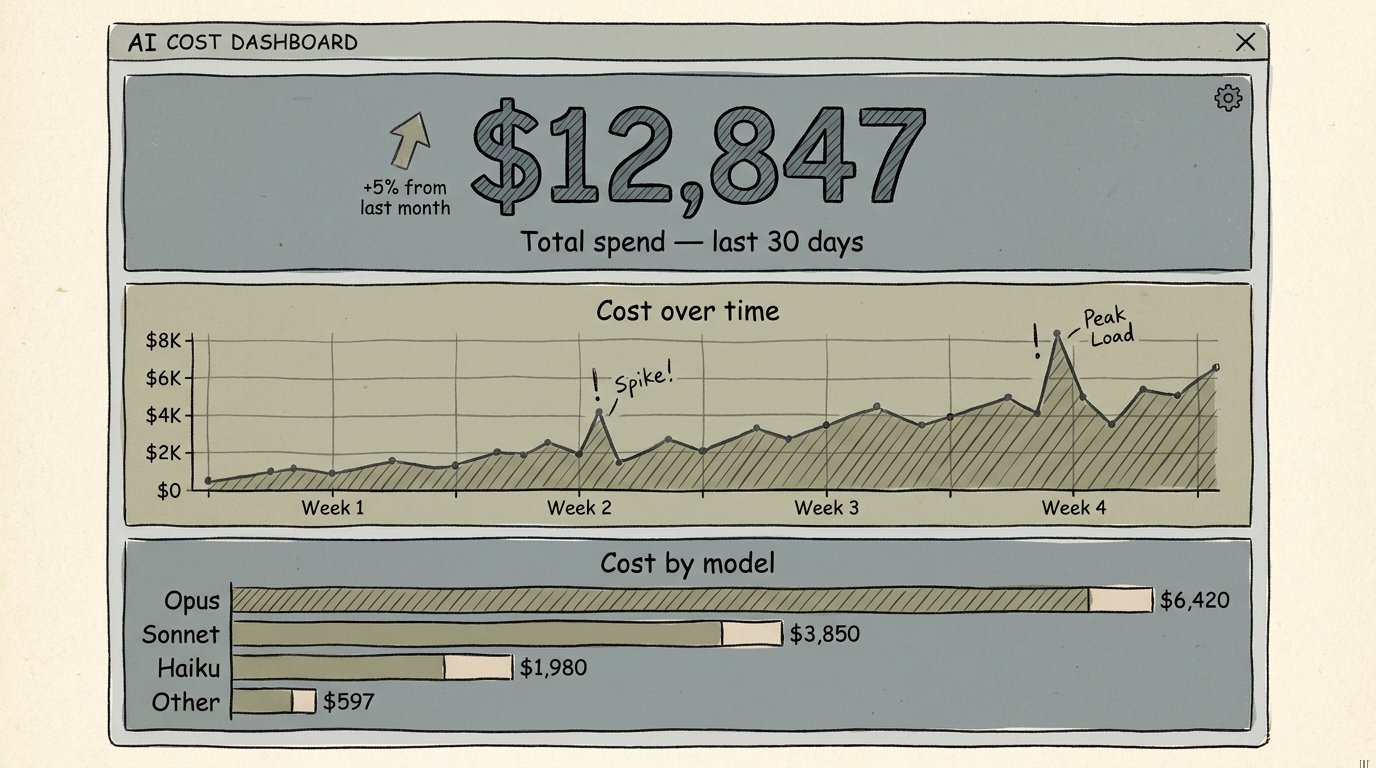
They do not answer the harder question: of the $X I spent, which specific calls or sessions or prompts would have produced equivalent outcomes for less money? That question requires a quality-equivalence claim, and quality-equivalence claims need evidence. A cost column does not provide one.
Several dashboards now show “savings opportunities” or similar: generic suggestions of the form “you’re using Opus for tasks Haiku could handle.” These are not wrong, exactly. They are not specific. They cannot tell the user which of their tasks could be safely downgraded, because they have not looked at the tasks. They are the cost-tool equivalent of “you should exercise more”: true, generic, and not actionable.
Why recommending is harder than reporting
Reporting is summation. You walk the spans, you multiply by the rate, you display the total. The math is mechanical.
Recommending is inference. To say “47% of your sessions would have completed on Haiku” is to assert something about quality equivalence on a workload nobody has actually run on Haiku. That assertion is the entire game. If the recommendation is wrong, the user applies it, their work breaks subtly, and they lose trust in the tool forever. The downside of a bad recommendation is much larger than the upside of a vague one, which is why responsible cost dashboards stop at reporting.
The escape from this trap is to make the recommendation evidence-backed. Not “Haiku is generally good at coding tasks” (which is a benchmark claim, useful but not actionable for a specific team). Instead: “we sampled 8 of your flagged sessions, replayed them through Haiku, and 7 of 8 produced equivalent tool-call sequences.” That is a different claim. It is grounded in the user’s own data. It can be wrong, but it shows its work, and the user can read the evidence and decide.
The validation step, in technical detail
The mechanism that makes this work is straightforward enough to describe.
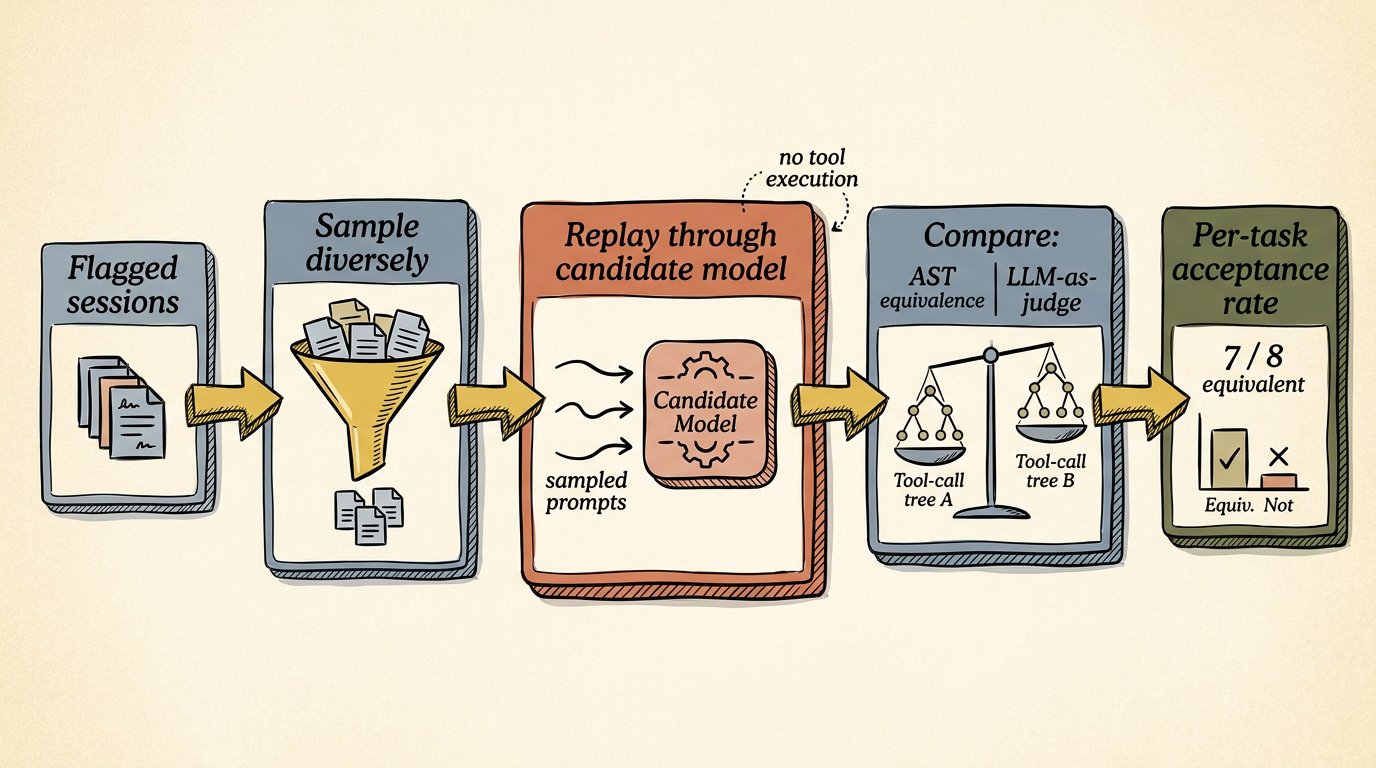
Start with structural heuristics. Look at the user’s session history, flag sessions that match patterns historically suitable for cheaper models: short input, short output, few tool calls, simple control flow. This is the first pass and it ships in roughly the same shape as the generic “savings opportunities” features already in some tools. It is fine. It is also Level 1 evidence, and the recommendation should say so.
Then validate. Sample a handful of the flagged sessions diversely (stratified by tool-call signature), reconstruct the original prompts from the spans, and replay each prompt through the candidate cheaper model. Do not execute any tool calls during validation. The point is not to re-run the work; the point is to capture what the cheaper model would have produced as its next step.
Compare the responses. There are two cases worth treating separately:
For tool-using sessions (most coding-agent workloads), the right comparison is structural. The Berkeley Function Calling Leaderboard (Patil et al., ICML 2025) established AST equivalence as a defensible test for tool-call agents: extract the tree of tool invocations from each response, compare structurally with reasonable tolerance for argument fuzziness (file paths may differ slightly, queries may use synonymous phrasing). If both models produce the same tool-call tree, they interpreted the task the same way. The validation cost is exactly one LLM call to the cheap model; no tool execution, no environmental side effects.
For non-tool sessions (Q&A, summarization, generation), AST equivalence does not apply. The right comparison is LLM-as-judge: a third model, ideally from a different family than either candidate, scores whether the two responses are equivalent for the user’s request. This is more expensive than AST equivalence (you’re paying for the judge’s call), but the cost is still bounded by sample size, not by workload size.
The total validation cost on a representative sample is in the range of $0.30 to $1.00 per analysis run, which is small compared to a workload that is burning tens or hundreds of dollars per day on the workloads being validated.
A three-tier confidence framework
The output of all this is a recommendation with explicit confidence. Three levels.
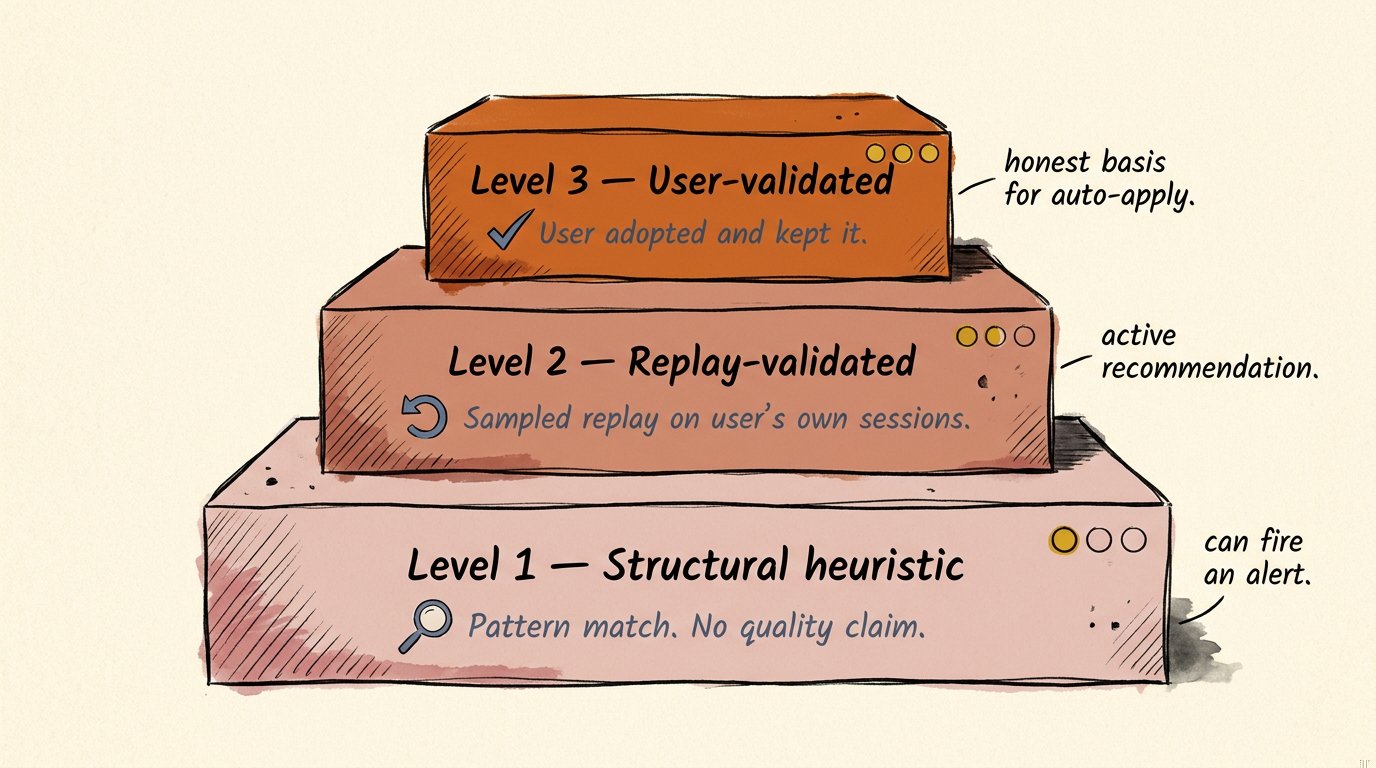
Level 1: structural heuristic. Pattern matching against the user’s data, no quality claim. “These 116 sessions match the structural shape of workloads that historically run acceptably on smaller models.” Useful as a candidate list. Should always be presented with caveat language, never as a quality assertion.
Level 2: replay-validated. Sampled replay against the user’s own sessions with AST or LLM-as-judge comparison. “We sampled 8 of these sessions; 7 of 8 produced equivalent tool-call sequences on the cheaper model.” Mid-cost, evidence-backed, can be defended.
Level 3: user-validated. The user applied the recommendation, continued working, did not roll it back, did not show signals of subtle quality regression (no rage-edits, no manual model upgrades on similar tasks, no rerun churn). After N successful instances across diverse sessions, the recommendation graduates to “we’ve seen this work for you across many real tasks.” Zero ongoing cost; highest confidence; accumulates over time.
The framework matters because it determines what kind of automation can sit on top. A Level 1 finding can fire an alert. A Level 2 finding can drive an active recommendation the user reviews. A Level 3 finding is the only honest basis for automatically applying a change. Every step of automation needs to be tied to the level of evidence underneath it, or the system stops being honest.
Why this hasn’t shipped credibly yet
The pieces have been available for at least 18 months. The research papers were public in 2023 (FrugalGPT, GPTCache, LLMLingua), got sharper in 2024 (LLMLingua-2, BudgetMLAgent), and matured into agent-specific work in 2025 (BFCL, RouteLLM, Budget-Aware Tool-Use, Agentic Plan Caching). The techniques compose. None of them are individually hard to implement.
The reason no shipping product runs the full assembly is structural, not technical. The product categories that exist today were each built to do something else.
LLM gateways sit in the runtime call path. Their natural posture is intercept-and-route, not offline-analyze-and-recommend. Adding validation runs means standing up parallel infrastructure that isn’t part of their core competence, and their commercial model is built around traffic, not analysis.
Observability platforms have the trace data. Their natural commercial position is dashboards and trace exploration. Spinning up cost-incurring validation runs against their users’ models is not adjacent to what they sell, and the privacy posture required for it (replay on a sample of the user’s actual prompts) does not map cleanly to their multi-tenant cloud setups.
Research artifacts (the FrugalGPT / RouteLLM / LLMLingua / GPTCache lineage discussed earlier in this series) provide the techniques without a product surface, without integration into the agent telemetry that a real workload produces, and without any concept of user-specific data validation. They are libraries, not tools.
Local cost-capture utilities are upstream of all this. They report what happened. They are useful, but they are not the recommendation layer.
The gap between “the techniques exist in research” and “a developer can adopt the techniques in an afternoon” is the entire commercial space. It runs locally on the user’s data, it does the validation step the user can audit, it produces specific changes with explicit confidence levels, and it integrates with whatever the user already uses without sitting in the call path.
What this means going forward
The cost discipline category will see new entrants in the next quarter. Most will start as cost dashboards (because that is the easier surface to ship) and pitch themselves as “AI cost observability” or similar. Some will add generic recommendations on top of the dashboard (“consider downgrading”). A few will eventually build the validation layer described above.
The ones that survive are the ones that emit recommendations a user can trust, which means recommendations with explicit evidence at explicit confidence levels. A dashboard that reports the bill is necessary but not sufficient. A recommendation engine without validation is worse than no recommendation engine at all, because it burns trust as soon as the first bad suggestion ships. The honest version sits between those two, runs on the user’s own data, declares its confidence, and gets out of the way once the user has decided what to apply.
Common questions
- Doesn't a cheaper model just produce worse output?
- Sometimes. That is exactly what validation is for. The point is not to assume Haiku is good enough generically; it is to determine, on this specific user's actual workload, which sessions Haiku handled equivalently to Opus and which it did not. The 7-of-8 figure used as an example throughout this post is illustrative, not universal. The actual rate for a given team depends on their work, which is why running the validation against their data is the load-bearing step.
- Why not just run benchmarks against my workload?
- Benchmarks like SWE-bench or GAIA tell you how a model does on someone else's tasks. They do not tell you how the model would have done on your tasks. Your CLAUDE.md, your tool selection, your style of prompting, and the workflow context your agents operate in are all different from the benchmark setup. The general capability signal from benchmarks is useful for narrowing the candidate list; it is not a substitute for actually checking against your own data.
- What about cost views in observability tools?
- They report. They are good for what they do, and they remain the right place for the cost-time-series substrate. They are not the recommendation layer, and the structural reasons for that are described above. The natural integration is for an analysis tool to ingest from the observability tool's trace data, run the analyses described here, and produce the recommendations that the observability tool's commercial model does not motivate it to build itself.
- Why does validation need to be opt-in?
- Because validation costs money. A user with thousands of flagged sessions, replayed naively, could spend more on validation than the analysis would ever recover. The opt-in flag plus a configurable budget cap (default low) is the discipline that prevents the analysis tool from accidentally burning the user's money. Validation is also a privacy-relevant step: it sends the user's prompts to alternative model providers, which the user should explicitly authorize on a per-provider basis.
- How does the user-validated tier work in practice?
- The recommendation gets applied (the user changes a config setting, or accepts an MCP-suggested routing rule). The analysis tool continues to observe new sessions matching the same pattern. If the user does not roll back, does not show signs of unhappiness with the output (manual model upgrades, redo churn, explicit this-was-wrong feedback), the rule accumulates positive signal. After enough successful applications across diverse sessions, the recommendation graduates from candidate to user-validated default and can be a basis for higher-confidence automation. This takes weeks of normal usage to mature, not days.