The problem with TokenMaxxing
Why it matters
I’ll be honest: I love TokenMaxxing. For a few months now I’ve squeezed more than $4,000 of tokens a month out of my $100 Claude Max 5x plan. Here’s last month:
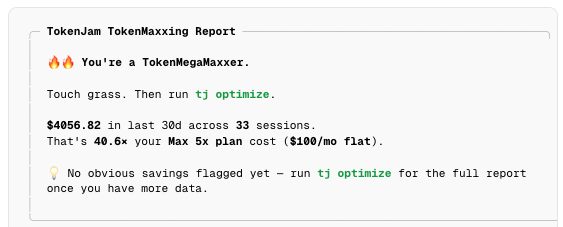
If you’re curious how this was generated, it’s our TokenMaxxing page. Run tj tokenmaxx and you’ll get the same report for your own account in under a minute. The number is usually higher than people expect.
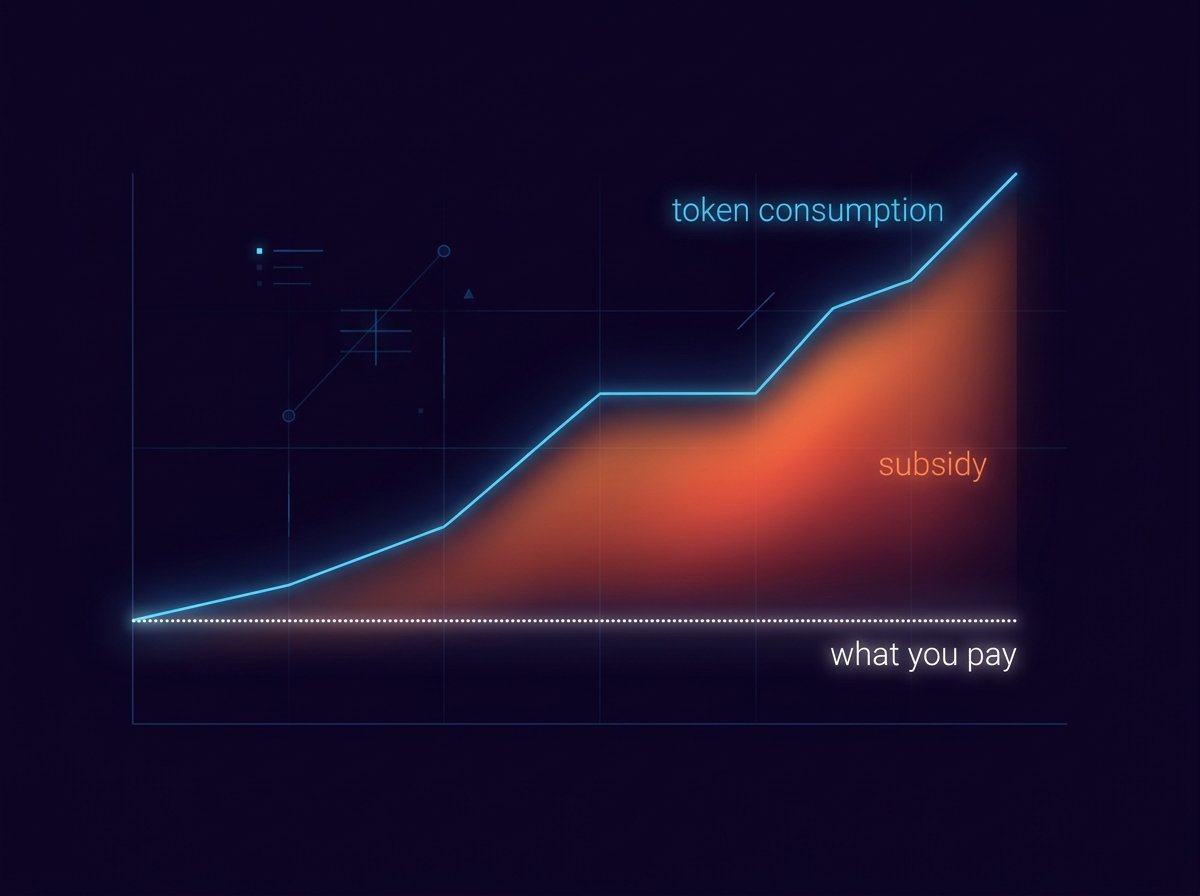
So why am I writing a post called The problem with TokenMaxxing? Because that 40× figure is not a win I earned. It’s a subsidy, and the subsidy is ending.
For about eighteen months, the smartest move in agentic coding was to pay a flat subscription fee and then use it as hard as humanly possible. Run Claude Code overnight. Fan out ten agents. Let the thing rewrite the whole module instead of the one function. The marginal cost to you was zero, so the rational consumption level was infinity. People turned this into a sport, screenshotted their implied bills, and compared multiples. The bigger your number, the harder you were maxxing.
The sport was always built on a quiet assumption: that the provider would keep eating the difference. That assumption stopped being safe this quarter. If your workflow depends on a 20× or 40× multiple staying free, it’s worth understanding what that multiple actually is and why it’s about to get expensive.
Where the word came from
The “-maxxing” suffix arrived from internet subculture, where looksmaxxing and similar terms described optimizing one variable to its absolute ceiling. Developers borrowed it for token usage sometime in early 2026, around when the first viral Claude Code bill screenshots started circulating. Once you could read your local session logs and put a dollar figure on a flat-rate month, the comparison game wrote itself.
The framing caught on because the numbers were genuinely startling. A developer paying $100 a month would discover they had consumed $3,000 or $4,000 of tokens at list API prices. That felt like winning. The screenshots got tiers, the tiers got names, and “are you tokenmaxxing hard enough?” became a real question people asked each other.
The part that got lost in the meme is what the multiple represents.
The part everyone skips: it’s a subsidy, not a hack
A 40× multiple is not a clever exploit. It’s a measurement of how much money your provider is losing on you.
Why would anyone run a product line at a loss on purpose? Because AI is in a land-grab. OpenAI, Anthropic, and xAI are competing for the same scarce thing right now, which is users and habit, not profit. The cheapest way to win a developer is to make the tool feel free until it’s load-bearing in their daily workflow, and then keep them. Flat-rate subscriptions are the acquisition coupon, and the gap your tokenmaxx multiple measures is the marketing budget.
The tell is the distance between what these companies charge for a subscription and what they charge for raw API access. The subscription is the price to get you in the door. The API price is closer to what the tokens actually cost to serve, plus margin. When a $100 plan reliably delivers thousands of dollars of API-rate value, the subscription is the marketing number and the API is the honest one.
xAI took the strategy to its logical end. Grok is free for every user on X, with Grok 4 rolled out free worldwide at generous usage limits, while the same capability metered through the xAI API costs real money per token. Free chat buys the user; the API line shows the bill. Anthropic and OpenAI run a quieter version of the same play through flat Pro and Max tiers, where heavy use is absorbed rather than priced. The mechanism is the same in all three cases: subsidize the front door, meter the back.
We made the broader case in the era of subsidized AI may be coming to an end. The short version: flat-rate subscriptions were priced when usage was low and casual. Then agents got autonomous, sessions started running for hours unattended, and per-user consumption went up by an order of magnitude. Microsoft began cancelling Claude Code licenses across its Windows and M365 engineering org. Uber gave 5,000 engineers Claude Code in December and burned its full annual AI budget by April. A leanopstech audit of 30 teams found a 20× cost spread between the lightest and heaviest developers on the same tool.
When you tokenmaxx, you are the heavy developer. Your multiple is the provider’s loss, recorded from the other side of the ledger. That’s fine while the provider is willing to subsidize growth. It stops being fine the moment they decide they aren’t.
Fable 5 made the subsidy visible
The clearest recent signal is Claude Fable 5, which Anthropic released on June 9. It’s a public, classifier-guarded version of the Mythos-class model, and on capability it’s a real step up. On cost, it tells you exactly where the industry is heading.
Three things stack:
First, the sticker price. Fable 5 lists at $10 per million input tokens and $50 per million output, which is twice Opus 4.8’s $5 and $25.
Second, the verbosity. Fable 5 generates much longer outputs than its predecessors. On the Artificial Analysis Intelligence Index it produced 86 million tokens against a field average of 36 million. Call it roughly 2× the token volume to do comparable work. Double the price per token, double the tokens, and the effective spend per task lands near 4× Opus for a lot of workloads.
Third, and this is the tell: Fable 5 is free on Pro, Max, Team, and Enterprise plans only through June 22. On June 23 it leaves the flat plans and continued use bills against usage credits at API rates, with no committed date for re-inclusion. The most capable model Anthropic has shipped to the public gets a two-week subsidized window, then moves to metered billing. That is the subsidy being switched off in real time, on the single product where you’d most want to tokenmaxx.
This is not an isolated policy. Anthropic’s programmatic credit cap takes effect today, June 15: Pro plans get $20 of API-equivalent credits per cycle, Max 5x gets $100, Max 20x gets $200, and past the cap full API rates apply. GitHub Copilot moved to usage-based billing on June 1. Two of the largest coding-agent surfaces started metering what used to feel free, in the same fifteen-day window.
What your multiple actually looks like
Mine is high, but it’s far from the top. Here’s a TokenGigaMaxxer at 68× their plan:
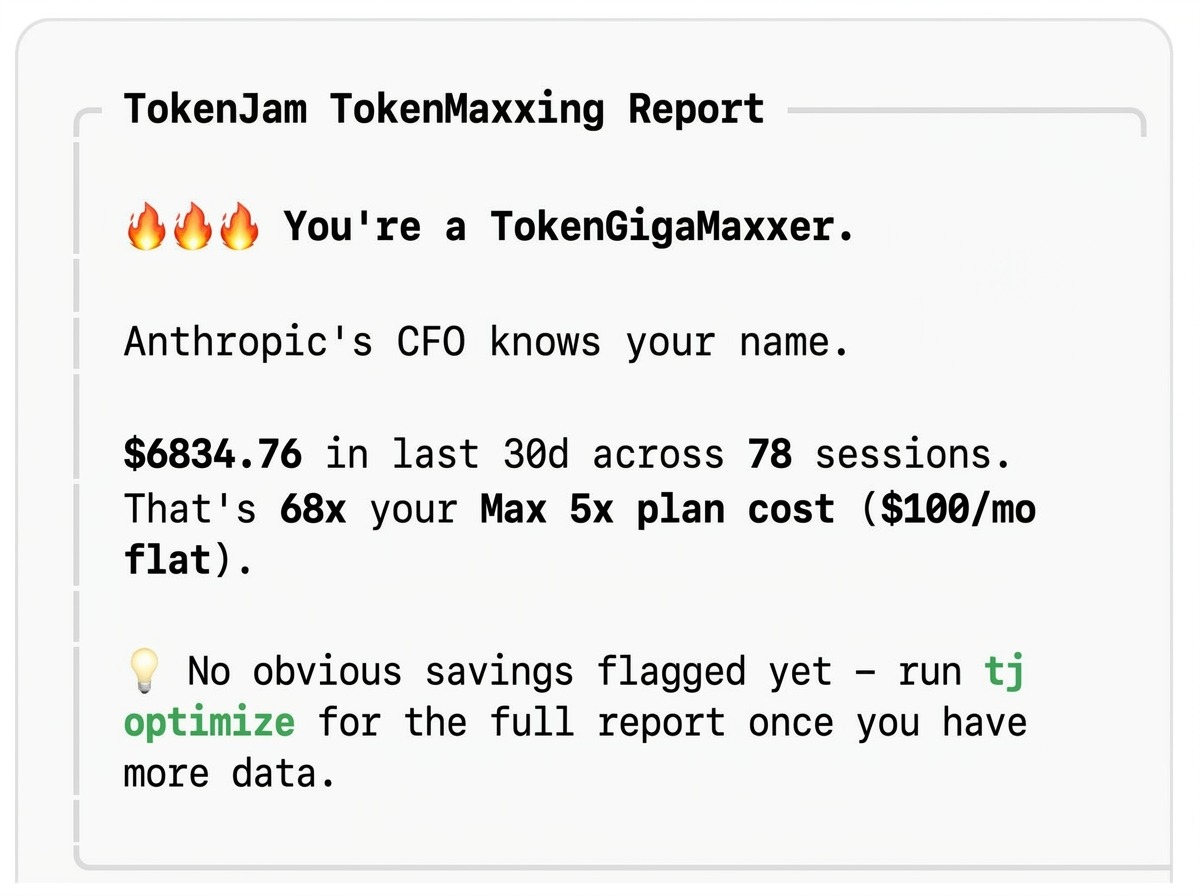
$6,834 of API-equivalent value on a $100 plan. A 68× multiple. Under the subsidy, that reads as a flex. Read against the credit cap that lands today, it reads as a forecast: that’s roughly what this person’s usage will cost once the flat-rate cushion is gone and the meter is running.
The tiers people share map directly to how exposed they are when the subsidy ends:
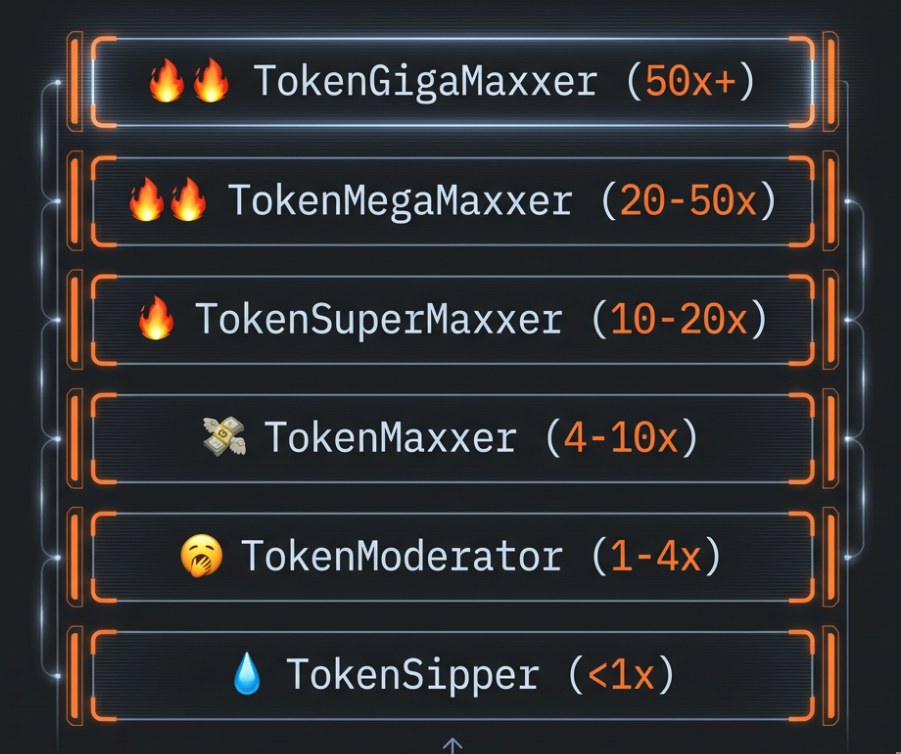
| Tier | Multiple | What it means |
|---|---|---|
| TokenSipper | < 1× plan | Barely using it. No exposure. |
| TokenModerator | 1× to 4× | Mostly paying your own way. |
| TokenMaxxer | 4× to 10× | You’re paying Anthropic’s rent. |
| TokenSuperMaxxer | 10× to 20× | And their interns’ rent. |
| TokenMegaMaxxer | 20× to 50× | Most of it is subsidy now. |
| TokenGigaMaxxer | 50×+ | The whole gap is subsidy. |
A TokenSipper feels nothing when caps arrive. A TokenGigaMaxxer feels the entire difference between $100 and seven thousand.
Why this can’t keep going
There are two reasons the subsidy is structurally temporary, one operational and one financial.
The operational one is usage. The numbers from last quarter were not edge cases. Uber’s full-year AI budget went in four months. A single developer in the leanopstech audit ran up $4,200 over one long weekend during an autonomous refactor. The healthcare enterprise that quietly consumed a trillion tokens in six months booked over $6 million in unplanned cost. As agents get more autonomous and sessions run longer without a human in the loop, the average multiple climbs, which means the subsidy per user climbs with it. A subsidy that grows with adoption is the opposite of a business model.
The financial one is the IPO horizon. Several of the providers underwriting these flat plans are on a path to public markets. Private companies can run negative gross margin on a product line and call it growth. Public companies get repriced the quarter after they file, on earnings per share and on margin, by analysts who treat subsidized inference as exactly the kind of line item you cut to show a path to profitability. Once the story has to be EPS growth instead of usage growth, “we let power users consume 40× their subscription fee” is the first slide that gets challenged in the board meeting. The companies can’t keep losing money on the heaviest users indefinitely, and the moment public-market discipline arrives, they won’t.
Could specific policies get walked back? Sure. Caps can expand, a free window can get extended, a seat price can quietly absorb more value for a while. The direction does not reverse. The multi-year trajectory is that agent users feel their token consumption directly. Tokenmaxxing as a free sport has an expiry date, and the dates on the calendar this month are the first installments.

What to do about it
The honest answer is not “stop using agents.” It’s “know your multiple, then make it smaller on purpose.”
Most people have never actually measured theirs. They have a vibe, not a number. The first step is to turn the vibe into a figure, because you can’t manage exposure you can’t see. If you’re running Claude Code, you already have the data sitting in ~/.claude/projects/. Reading it takes three commands:
pipx install tokenjam
tj onboard --claude-code
tj tokenmaxxNo signup, runs locally, reads 30 days of history. Find out how hard you’re tokenmaxxing →
The tier is the shock value. The point is what comes after it. Once you know your multiple, tj optimize looks at the same history and flags where it came from: sessions where a cheaper model would have produced the same result, prompt context you’re re-sending every call, prefixes you could cache, deterministic sequences you could replace with a script. The leanopstech audit found that 62% of the average agent bill is re-sent context doing no useful work. That’s the part of your multiple you can cut without changing what you build.
The era where the number was a brag is ending. The era where it’s a line item you own starts this month. Better to find out where you stand before the meter does it for you.
Common questions
- Is a high tokenmaxx multiple a bad thing?
- Not for you, while the subsidy lasts. It means you're getting far more value than you pay for. The risk is that the whole multiple above 1x is provider subsidy, and your effective cost converges toward the metered figure as caps and usage billing roll out. A 40x multiple today is a preview of your bill once the flat-rate cushion is gone.
- Does the June 15 credit cap mean my Claude Code stops working?
- No. Interactive use in the terminal and Claude.ai chat stays on existing subscription limits. The cap applies to programmatic use: the Agent SDK, claude -p, GitHub Actions, and third-party apps built on the SDK. Pro gets $20 of API-equivalent credits per cycle, Max 5x gets $100, Max 20x gets $200, then full API rates apply. A light user won't notice. A heavy programmatic user runs out partway through the cycle.
- Why did Fable 5 only stay free on plans for two weeks?
- Capacity and economics. Fable 5 is roughly 2x Opus 4.8 on price and about 2x more verbose per task, so it's expensive to serve. Anthropic gave subscribers a free evaluation window through June 22, then moved it to usage credits on June 23 with no committed date to bring it back into flat plans. It's the clearest single example of a subsidy being switched off on a frontier model.
- Is my Claude Code session normal if it's costing $200 in a weekend?
- It's common, not abnormal. Long autonomous runs rack up cost fast, especially with a verbose model and large re-sent context. In one audited team a single developer hit $4,200 over a weekend on an autonomous refactor. The fix is rarely 'use it less' and usually 'find the share of the spend that wasn't buying useful work,' which for most teams is the majority of re-sent context.
- How do I find my own multiple without signing up for anything?
- If you use Claude Code, run pipx install tokenjam, then tj onboard --claude-code, then tj tokenmaxx. It reads your local ~/.claude/projects/ logs, computes 30 days of implied API value against your plan fee, and prints your tier. It's open-source, MIT-licensed, and runs entirely on your machine.
- If the subsidy is ending anyway, why optimize now instead of waiting?
- Because the optimizations are the same work either way, and doing them before the meter turns on means you never pay for the waste. Right-sizing the model per task, trimming re-sent context, and caching stable prefixes lower your real consumption whether you're on a flat plan or metered billing. The only difference is whether you capture the savings or hand them to the provider.
Further reading
- The era of “subsidized AI” may be coming to an end. The data behind the subsidy thesis.
- Where your agent bill actually goes. Why most of a token bill isn’t buying useful work.
- Claude Fable 5 and Mythos 5 pricing and benchmarks. Full pricing and benchmark breakdown.
- GitHub Copilot is moving to usage-based billing. The other half of the June metering shift.