What is AI model autorouting?
Why this is suddenly everywhere
A year ago most teams picked one frontier model and pointed everything at it. That worked when there were two or three models worth using. Now there are dozens across every provider, and they vary wildly on price and on what they’re actually good at. The same prompt can cost sixteen times as much on a flagship model as on a budget one in the same family.
Coding agents made the gap impossible to ignore. An agent doesn’t make one call per task. It loops, re-sends context, and racks up hundreds of LLM calls in a single session (see what is an agent loop). When every one of those calls hits the most expensive model by default, the bill grows fast and most of it pays for capability the task never needed.
A note on “models,” since the coding case trips people up. The model powering your coding agent is a language model too. Routing isn’t a separate technique for chat versus code; it’s the same idea applied to whichever LLM is doing the work. And coding is where the mismatch is most obvious. Renaming a file, fixing a typo, nudging a CSS value, regenerating a snapshot test: none of that needs a frontier reasoning model. Yet a coding agent will happily send “rename foo to bar” to the same model it uses to redesign your auth flow, at the same price. The cosmetic change runs fine on a small, fast model for a fraction of the cost.
That’s the opening AI model autorouting walks into. If you could send the typo fix to a small model and reserve the architecture refactor for the big one, you’d keep the quality where it matters and stop overpaying everywhere else.
The three things people call “routing”
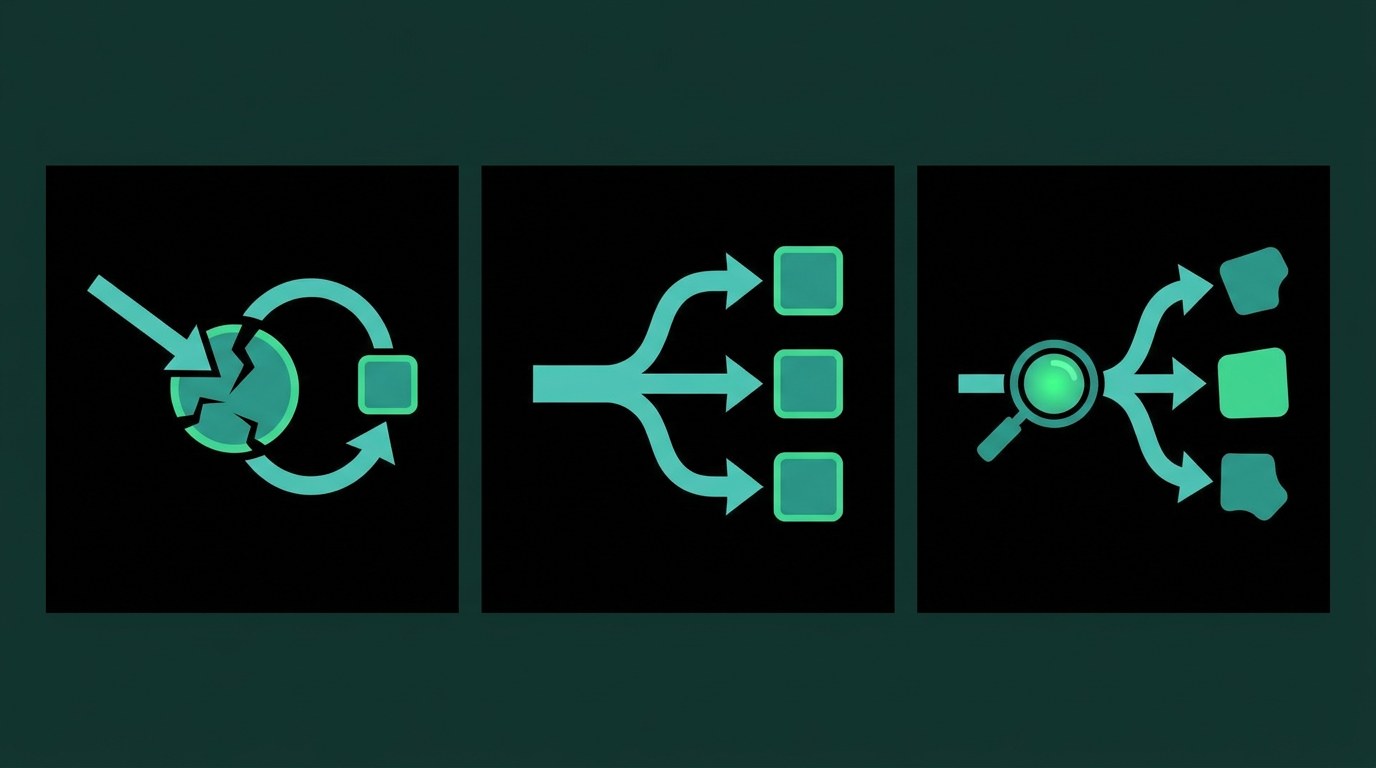
The word “routing” covers three mechanisms that do very different jobs. Sorting them out is the fastest way to cut through the marketing.
The first is failover. The primary model errors or times out, so the request falls through to a backup. This is a reliability feature. It keeps your app up when a provider has a bad minute. It makes no judgment about which model is right for the request.
The second is load balancing. Traffic gets split across providers or keys by weight, latency, or rate-limit headroom. Useful at scale, still indifferent to what the request actually contains.
The third is the interesting one: prompt-aware routing. The router looks at the request, predicts which model will handle it well, and sends it there. This is what people mean by autorouting. The decision depends on the content, not just on which endpoint happens to be healthy or cheap right now.
Failover and load balancing are solved problems. Prompt-aware routing is where the research and the hard tradeoffs live, so that’s the rest of this post.
How a prompt-aware router decides
A router needs to answer one question fast, before the real model runs: is this request easy enough for a cheaper model, or does it need a stronger one? A few families of techniques have emerged.
Classifier-based routing trains a small model to predict the winner. You feed it the prompt and it outputs a routing decision. RouteLLM trained exactly this kind of classifier on human preference data from Chatbot Arena, learning to tell “weak model is fine” from “needs the strong model.”
Embedding (semantic) routing skips the trained predictor. It turns the prompt into a vector and matches it against labeled examples for each route, then sends the request wherever the nearest neighbors point. No extra model call to make the decision, which keeps routing overhead low.
Predictive routing estimates per-model quality (and sometimes cost) for the specific prompt, then optimizes the tradeoff. This is the line of work behind Chip Huyen’s “predictive human preference” framing, which RouteLLM builds on directly.
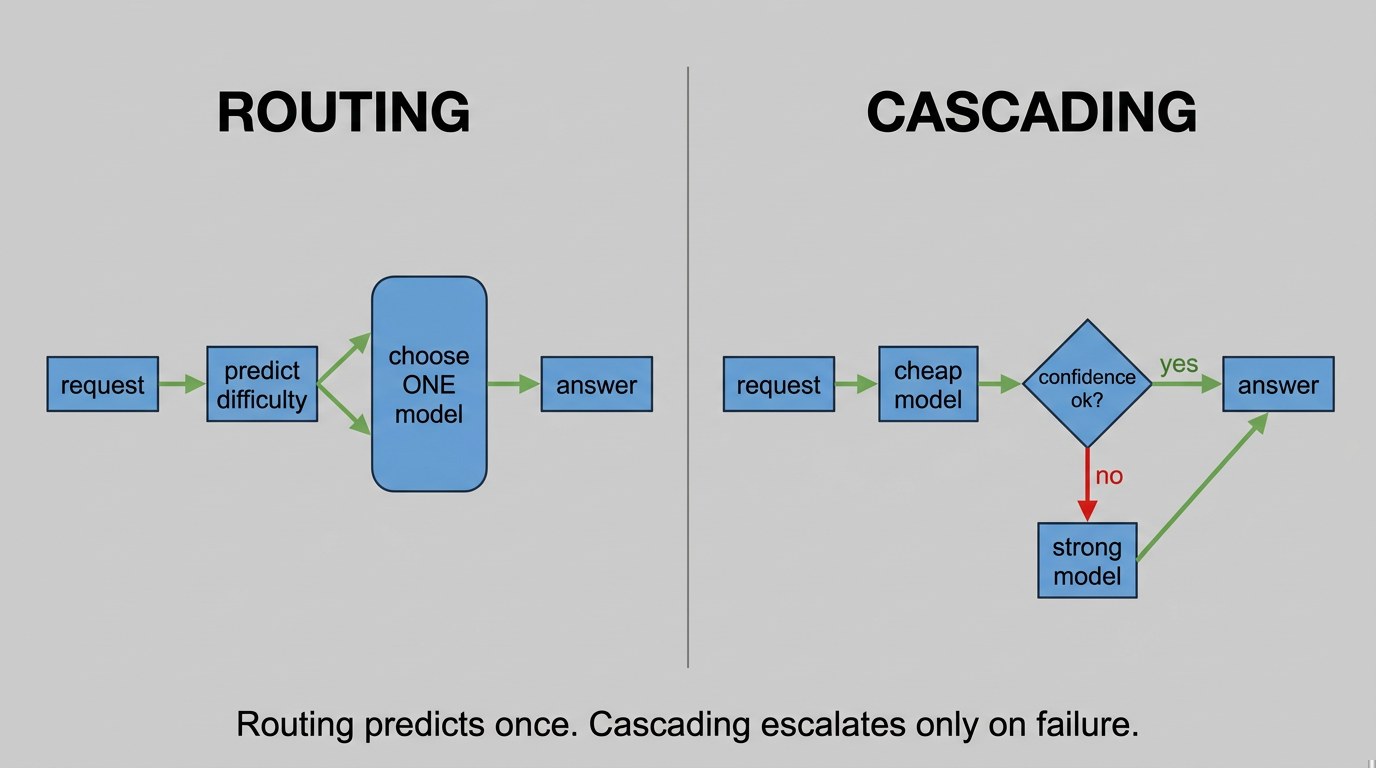
Cascading is a close cousin worth naming. Instead of deciding up front, a cascade tries the cheap model first, checks whether the answer clears a confidence bar, and only escalates if it doesn’t. FrugalGPT is the canonical example. Routing makes one decision and one call; cascading may make several, trading extra latency for not having to predict difficulty in advance.
Most real systems also expose a dial: a knob from “always pick the most capable model” to “always pick the cheapest.” Where you set it depends on how much quality you’re willing to risk to save money, and that answer is different for a customer-facing agent than for a batch summarization job.
What the research actually shows
The headline numbers are strong, and they come with fine print worth reading.
RouteLLM, from LMSYS and Berkeley (ICLR 2025), reported retaining about 95% of GPT-4’s performance while routing a large share of queries to a much cheaper model, with cost reductions over 85% on MT-Bench in their best configuration. The catch is that those figures are benchmark-specific and tied to a particular two-model setup. They’re a strong proof of concept, not a guarantee for your workload.
FrugalGPT (Stanford, 2023) made the economic case underneath all of this. It documented LLM API prices differing by two orders of magnitude for comparable tasks and showed a cascade matching top-model accuracy at a fraction of the cost. The “up to 98% cheaper” number it’s known for is a best case on specific datasets.
Hybrid LLM (ICLR 2024) is the most measured of the three. It routes between a small and a large model by predicted difficulty against a quality target you set, and reported up to 40% fewer calls to the large model with no drop in answer quality. That 40% is closer to what a careful production router tends to deliver than the 85% to 98% best cases.
If you want to compare routers honestly, RouterBench is the standardized benchmark, built on over 400,000 measured inference outcomes. The pattern across all of this work is consistent: every router is trained or tuned on measured per-model quality and cost. The measurement is the input, not an afterthought.
You can’t route what you haven’t measured
Here’s where most “just turn on routing” advice falls apart. A router can only help if it knows two things about your traffic: which requests are over-provisioned, and what each model actually costs you in practice. Neither is knowable from a vendor benchmark. It lives in your own session history.
Concretely, before you wire up any router you want answers to: what fraction of my agent’s calls are structurally small, the kind a cheaper model handles fine? Which sessions are paying flagship prices for typo-fix work? What would those calls have cost on a smaller model in the same family? Without those numbers you’re not routing, you’re guessing, and a misconfigured router that downgrades the wrong tasks quietly degrades quality while you congratulate yourself on the savings.
This is exactly the gap TokenJam Downsize closes. It walks every LLM call in your captured trace history, classifies each session by structural shape (input and output token counts, tool-call count, single- versus multi-turn), and flags the sessions that match a small-task pattern. Then it computes what those calls would have cost on a cheaper model and shows you the difference, grounded in your data rather than someone’s leaderboard. A real run against a Claude Code project flagged 47% of sessions as candidates for a smaller model, with the savings figure attached to each finding.
tj optimize --validate to replay-test on your actual sessions before applying. Downsize never claims the cheaper model would have produced an identical answer. It surfaces candidates with evidence and leaves the call to you. Under the hood it leans on the same research above: FrugalGPT’s cascade-confidence framing and RouteLLM as the routing engine for the validated tier. The structural pass ships in the open-source CLI; a replay-validated tier actually re-runs flagged sessions through the cheaper model and compares tool-call sequences before recommending anything.
Think of it as the step before routing. Downsize tells you where routing would pay off and where it wouldn’t. Once you know that, configuring a router (or just changing a default in your agent settings) is the easy part.
Where to start
The measurement runs locally and reads telemetry you already have, so there’s nothing to instrument first:
onboard reads your existing Claude Code session logs from the last 30 days. tj optimize downsize gives you the list of over-provisioned sessions with a dollar figure on each. If you’d rather see the one-line “how hard am I overpaying” version first, tj tokenmaxx reads the same history and prints a single shareable summary (more on that in the problem with TokenMaxxing).
Everything stays on your machine. No signup, no API key for TokenJam itself, telemetry never leaves your laptop unless you export it. The whole thing is MIT-licensed and on GitHub.
Routing is a powerful lever once you know which tasks to pull it for. Measure first, then route.
Common questions
- Isn't autorouting just picking a cheaper default model?
- No. A default model applies to every request regardless of content. Autorouting decides per request, so a hard task still gets the capable model while easy tasks drop to a cheaper one. A single cheaper default would degrade your hard cases; routing is what lets you avoid that.
- Does this only apply to chat models, or to my coding agent too?
- Coding agents run on language models, so the same routing idea applies directly. Coding is actually the clearest case for it. Renaming a file, fixing a typo, or making a cosmetic CSS change doesn't need a frontier reasoning model, but most agents send those edits to the same expensive model they use for a real refactor. Those trivial edits are exactly the sessions Downsize flags as candidates for a smaller, cheaper model.
- My agent bill is huge but I have no idea which calls are wasteful. Where do I even start?
- Start by reading your own session logs, not by changing models. Run tj optimize downsize against your last 30 days of history. It groups your calls by structural shape and tells you what fraction are small enough that a cheaper model would likely have handled them, with the savings attached. Now you have a target instead of a guess.
- How much does routing actually save in practice?
- Vendor headlines cluster around 20% to 35% for general production traffic, with research best cases (RouteLLM, FrugalGPT) reaching 85% and higher on specific benchmarks. The honest band for most teams is the lower one. Your real number depends entirely on how much of your traffic is over-provisioned, which is why you measure before you commit.
- Will routing to a smaller model quietly hurt quality?
- It can, if you route the wrong tasks. That's the actual risk, and it's why a structural flag is a candidate, not a command. Replay-validation (re-running a sample of flagged sessions through the cheaper model and comparing the tool-call sequences) is how you catch a bad downgrade before it ships, rather than discovering it in production.
- Do I need a routing gateway to benefit from this?
- Not to start. For coding agents, a lot of the win is just changing which model your agent uses for which kind of task, which can be a settings change or an exported config. A full prompt-aware gateway makes sense once you're routing high volume across many models and want the decision made automatically per request.
- What's the difference between routing and cascading?
- Routing predicts the right model up front and makes one call. Cascading tries the cheap model first and escalates only if the answer fails a confidence check, which can mean several calls. Routing trades a harder prediction for lower latency; cascading trades extra latency for not having to predict difficulty in advance.
Further reading
- RouteLLM: Learning to Route LLMs with Preference Data (LMSYS / Berkeley). The reference open-source router, with the cost/quality numbers and methodology.
- FrugalGPT (Chen, Zaharia, Zou, Stanford). The cascade-and-cost foundation the whole space builds on.
- Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing (ICLR 2024). The most production-realistic of the routing papers.
- RouterBench. A standardized benchmark for comparing routers across 400k+ measured outcomes.
- Predictive Human Preference (Chip Huyen). The model-ranking-to-routing framing that RouteLLM builds on.
- TokenJam Downsize. The measurement step before any router. Reads your own session history and flags the calls a cheaper model would have handled.
- What is agent observability?. Why measurement is the prerequisite for every optimization, routing included.