What is an agent loop?
Why it matters
On June 7, 2026, Peter Steinberger posted a sentence that cleared 2.2 million views and put the whole AI-coding timeline in a chokehold: “you shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.” The replies turned into a brawl over what it actually meant. The most-quoted answer, from Matthew Berman, was four words: “nobody knows but him and boris.”
That is the real story. A six-word phrase hit two million views while the people boosting it argued about what it meant. The idea underneath is not mysterious, though, and it is worth getting precise about, because it changes where your engineering effort goes and where your bill comes from.
The cleanest definition came from Boris Cherny, who built Claude Code, speaking at the Acquired Unplugged event on June 2: “I don’t prompt Claude anymore. I have loops that are running. They’re the ones that are prompting Claude and figuring out what to do. My job is to write loops.” Place yourself on his ladder and the shift gets concrete. A year ago he wrote code by hand with autocomplete. Then he ran five to ten Claude sessions in parallel and prompted each one. Now he does not prompt at all. He writes the loops, and the agents decide what to build next.
From prompting to looping
For the last two years, most people used agents one task at a time. The shape was human → prompt → agent → output. You ask for one thing, read the answer, fix the prompt, ask again. That works for small tasks. It falls apart on real work, because real work is not one prompt. It is a cycle: set a goal, make a plan, do the work, verify the result, repair what failed, then decide whether to stop, ask, or continue.
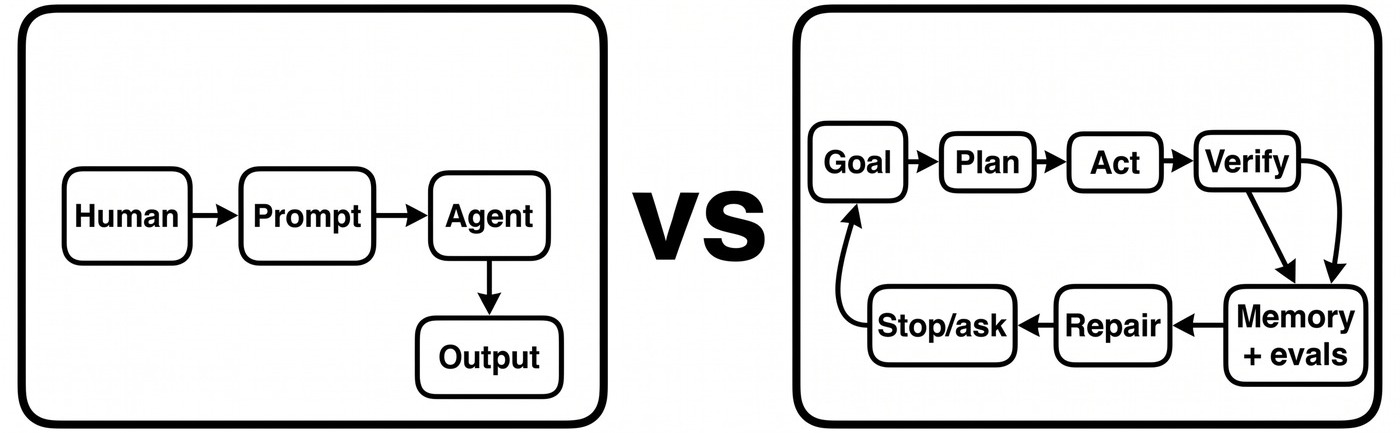 One-shot prompting versus the loop the agent runs inside.
One-shot prompting versus the loop the agent runs inside.
A loop is the program that runs that cycle for you. At its simplest, it is one agent working on itself: it researches, drafts, checks the draft against a goal, fixes what is weak, and runs the cycle again until the work clears the requirements. You are not prompting each step. The loop repeats the cycle on your behalf.
The shift is not “better prompts.” It is designing the system the agent runs inside. The human owns the goal, the boundaries, and the checks. The model owns the moment-to-moment decisions about what to do next.
The five-year lineage
The word “loop” hides at least five different things, which is why the replies to Steinberger’s tweet talked past each other. Here is the ladder, oldest to newest.
 Five rungs, oldest to newest.
Five rungs, oldest to newest.
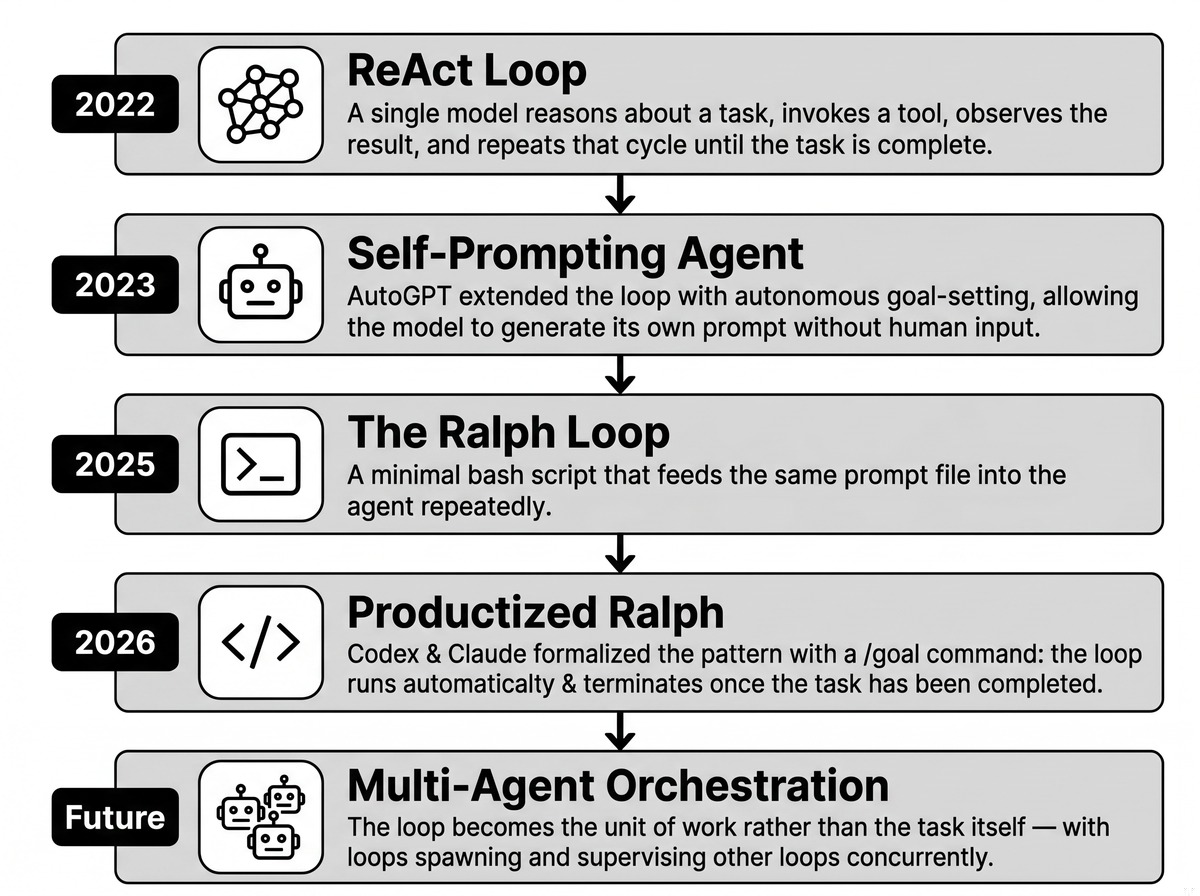
The first rung is the academic while-loop. The 2022 ReAct paper formalized it: the model reasons, calls a tool, reads the result, and repeats until done. One model, one loop, a human watching. Next came AutoGPT in 2023, which handed the loop a goal and let it prompt itself. It became famous for spinning forever while accomplishing nothing, and that failure seeded years of “agents are a toy.”
The third rung is the Ralph loop, published by Geoffrey Huntley in July 2025. It is almost insultingly simple: a bash one-liner that pipes the same prompt file into the agent over and over. Its real innovation was discipline. Every iteration resets the context to a fixed set of anchor files instead of letting the conversation grow without bound. Huntley built an entire programming language with it for around $297. In spring 2026, both Codex and Claude Code productized the pattern with a /goal command that runs the loop until a small validator confirms the task is done.
The fifth rung is what Steinberger and Cherny actually mean, and it is new rather than renamed. Four things changed. The loop became the unit of work instead of the task. Loops started supervising other loops, concurrently and on a schedule. Scheduling replaced the human kickoff, so a loop runs on infrastructure time rather than your attention. And durability became explicit, with git-backed state and crash recovery, because these things now have to survive a restart. Ralph assumed your terminal stayed open. The 2026 version assumes it does not.
Open loops and closed loops
The distinction that decides whether you can actually run a loop is open versus closed.
An open loop is exploratory. You give the agent a goal and a wide space to move in, and it can try different paths, discover things, and build something you did not fully spec. This is the exciting end, and it is where a lot of the hype lives. The catch is cost. An open loop with real room to explore burns an enormous amount of tokens, and pointed at a project with a loose standard it turns into a fast slop machine.
A closed loop is bounded. A human designs the end-to-end path first: a clear goal, defined steps, an eval at each step, and a point where it stops or hands back to you. The agent still loops, but inside a framework you built. It gets better every run because each pass feeds the next, and it runs on a normal budget because the path is tight.
You will see this carved up two ways. Some people use the two-mode split above. Others describe three levels: an open loop where work happens and nothing is captured, an end-to-end workflow that is written down yet static, and a closed loop that scores its output and writes the lesson back so run fifty is sharper than run one. The two framings line up cleanly. The middle “workflow” level is just a closed path that does not yet feed its results back into itself. For most production work, the bounded version is the one that pays off today.
Verification is the load-bearing part
The important part of a loop is not autonomy. It is verification. Without a way to check its work, a loop is just an agent confidently repeating its mistakes at scale. With verification, every run can produce signal: a wrong tool call points to a better tool boundary, a bad output points to a stronger eval, missing context points to better memory.
 The gate that turns a loop from a confident-mistake machine into something you can trust. (generated)
The gate that turns a loop from a confident-mistake machine into something you can trust. (generated)
This is why memory and evals sit next to the loop rather than off to the side. Memory gives the agent continuity across iterations. Evals give the loop a standard to measure against. Together they decide whether the work can be trusted. Boris Cherny’s own list of tips for running an agent autonomously for hours ends on exactly this point: make sure the agent has a way to self-verify its work end to end. An open loop that writes code with no feedback is a machine for generating confident mistakes. A loop that writes, runs, reads the result, and corrects is the thing that actually works.
The loop is now the expensive part
Here is where the topic turns from philosophy into a finance problem. Once the model writes the code for almost nothing, the cost moves to the loop running it. We covered the macro version of this in the end of subsidized AI: Uber capped its engineers at $1,500 per person per tool per month for Claude Code and Cursor after burning its annual AI budget in four months. When the loop is the unit of work, the loop is the unit of spend.
 When the loop runs while you sleep, the bill comes due in the morning.
When the loop runs while you sleep, the bill comes due in the morning.
The failure mode every team in production is scared of is the loop that does not stop. Without guardrails you get infinite loops and billing surprises orders of magnitude over budget. This is one of the named categories in where your agent bill actually goes: runaway loops are their own line item, distinct from context bloat or model overspending. Every serious write-up on loops converges on the same three hard stops: a maximum iteration count, no-progress detection, and a token or dollar ceiling. Setting and enforcing those caps across a fleet is the job of an agent control plane.
There is a fair skeptic’s line worth answering directly: isn’t this just a cron job with a hat on? Half right. The scheduling layer is cron, and Boris runs his on cron. What cron never had is the part in the middle. A cron job runs a fixed script. A loop runs a model that looks at the current state, decides what to do next, does it, checks whether it worked, and decides whether to keep going. The decision is the agent’s, not a hardcoded branch. A loop is cron plus a decision-maker in the body, and most of the interesting engineering is the guardrails you wrap around that decision so it does not run off a cliff.
Notable patterns and tools
The on-ramp and the deep end of agent looping, with what each one does.
/loopand/goalin Claude Code and Codex: built-in commands that run an agent toward a goal until a validator says it is done. The lowest-friction way to run a loop with no code to write.- The Ralph loop: the original bash one-liner that pipes a fixed prompt file into the agent each iteration, resetting context to anchor files. The reference implementation for “loop from first principles.”
- Gas Town (Steve Yegge): an open-source orchestration setup, with a “Mayor” agent coordinating 20 to 30 Claude Code instances and patrol agents running continuous loops, state stored in git so work survives a crash.
- roborev: a background tool that reviews every commit and feeds the findings back into the agent while the context is still fresh. An example of the verification layer that makes a loop trustworthy.
- Anthropic Agent SDK and OpenAI Agents SDK: for building the loop into your own app, with tool execution, session handling, and stop-condition control instead of a prebuilt slash command.
Common questions
- Isn't a loop just a while-true around my agent?
- The while-true is the easy 10%. The hard 90% is everything around the decision: the stopping condition, the verification step that decides whether a pass actually succeeded, the context discipline that keeps each iteration from ballooning, and the budget cap that halts it. A loop with none of that is a runaway. A loop with all of it is a system. The control flow is trivial; the guardrails are the work.
- My loop ran all night and burned $200 with nothing to show. What happened?
- Almost always an open loop with no stop condition and no verification. Three things to add. First, a hard cap: a maximum iteration count and a dollar ceiling, so it halts instead of grinding. Second, no-progress detection, so it stops when consecutive passes stop changing anything. Third, a real eval at the end of each pass, so 'done' is a checked condition rather than the agent's optimism. Open-ended prompts like 'improve this codebase' have no natural end and will run until the money does.
- Open or closed loop, which should I start with?
- Closed, for almost any real deliverable. Design the path first: clear goal, defined steps, an eval at each step, a defined handback point. You get repeatable results on a normal budget, and each run can feed the next. Open loops are worth it when the value is in discovery and you have the budget to explore, but pointed at a loose standard they produce fast, confident slop.
- Do I still need prompt engineering if I'm writing loops?
- Yes, it just moves. You are no longer hand-tuning one prompt per task, but the loop still prompts the agent each tick, and the quality of that prompt, the tool descriptions, and the eval criteria all decide whether the loop converges or thrashes. The reusable unit inside a good loop is a sharp, named, tested skill, not a one-off prompt. A loop calling vague prompts just burns money faster than you could by hand.
- How do I stop a loop from running forever?
- Three independent stops, because any one of them can fail. A maximum iteration count caps the number of turns. No-progress detection halts the loop when output stops changing across passes. A token or dollar budget ceiling stops it when spend crosses a threshold, which is the one that protects you from a billing surprise. Set all three. Treat the dollar ceiling as the backstop, not the primary control.
- Is multi-agent orchestration the same as a Ralph loop?
- No, and conflating them is most of the confusion in the discourse. The single-agent Ralph loop, one agent re-reading one prompt file, is the 2025 version and is old hat to practitioners. The 2026 thing Steinberger and Cherny are describing is a loop that supervises other loops, runs on a schedule rather than your keystroke, and keeps durable git-backed state so it survives a restart. Ralph is a rung on the ladder, not the top of it.
Further reading
- Ralph Wiggum as a “software engineer”. Geoffrey Huntley, July 2025. The original Ralph loop post.
- ReAct: Synergizing Reasoning and Acting in Language Models. Yao et al., 2022. The paper that formalized the reason-act-observe loop.
- Agents 101: Reasoning, Actions & Autonomy. The foundational definition of agents, the ReAct pattern, and levels of autonomy.
- Where your agent bill actually goes. The five categories of token waste, including runaway loops.
- What is an agent control plane?. The runtime layer that enforces budget caps and stop conditions across a fleet.