The 9-layer agent ecosystem map
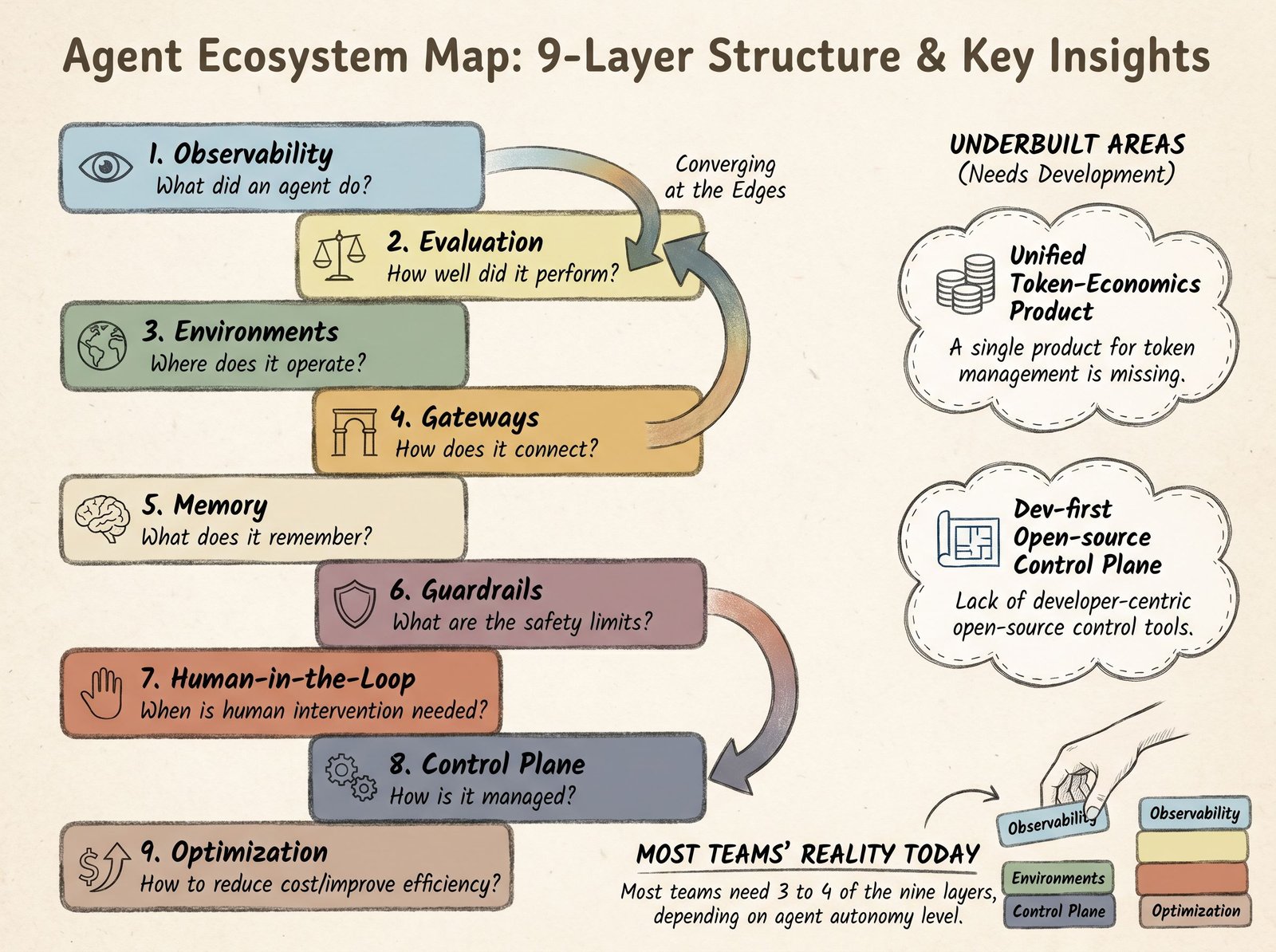
Reading the map
Over the past two-and-a-half weeks, this series has gone through the agent operations stack one layer at a time. It opened with a definition of what an agent even is and closed with the economics of what one costs to run. This post is the map: all nine layers in one place, the question each answers, the tools that occupy it, and the two places the ecosystem has not been built out yet.
Several of these layers were not categories two years ago. “Agent observability” was a phrase nobody used in 2023. The control-plane layer had no products at the start of 2026 and four credible ones by mid-year. The map below is a snapshot of a moving target. The nine questions are stable. The tools that answer them are not.
One note on how to read it. The layers are not a strict stack where each sits on the one below. They are nine concerns, and a single product can span two or three of them. What makes each a distinct layer is the question it answers, and the fact that most teams now buy or build for each one separately.
The nine layers
1. Observability: what did the agent do?
Observability is the capture layer. It records what an agent did in enough detail to debug, audit, and optimize it: every model call, every tool invocation, token counts, latencies, costs, and the reasoning chain connecting them. Agents are harder to observe than ordinary services because they are nondeterministic, deeply nested, and their real inputs and outputs are prompts and completions rather than structured payloads.
This is the most mature of the nine layers and the most crowded. Langfuse, LangSmith, Arize Phoenix, Braintrust, Helicone, AgentOps, Datadog LLM Observability, Pydantic Logfire, and Opik all compete here, increasingly on top of the OpenTelemetry GenAI semantic conventions as a shared schema. Full treatment: What is agent observability.
2. Evaluation: is the agent any good?
Evaluation measures whether an agent does what it is supposed to do, repeatedly, across the multi-step trajectories and tool use that single-turn model benchmarks never see. It splits along two axes: pre-built benchmarks, where you run your agent against someone else’s tasks, and frameworks, where you write your own.
Capability benchmarks include GAIA, SWE-bench, WebArena, OSWorld, TAU-bench, MLE-bench, and RE-Bench. Open-source frameworks include Inspect AI, DeepEval, Promptfoo, and RAGAS. Commercial platforms include Braintrust, Galileo, Maxim, and Patronus. One caveat worth carrying: a 2026 UC Berkeley study showed all eight major agent benchmarks could be gamed to near-perfect scores without solving the tasks. Full treatment: What is agent evaluation.
3. Environments: where can the agent safely act?
An environment is the isolated runtime where an agent acts: the sandbox holding the files, browser, OS, or tools it can manipulate, walled off from the developer’s machine. Isolation matters because agents make mistakes, and some of those mistakes are destructive.
Code-execution sandboxes include E2B, which uses Firecracker microVMs, and Modal. Browser automation runs on Browserbase with Stagehand. Daytona handles cloud development workspaces. HUD and the Prime Intellect Environments Hub host environments built for evaluation and reinforcement learning. Full treatment: What are agent environments and sandboxes.
4. Gateways: how does the agent talk to models?
A gateway is a unified API layer between your application and one or more model providers. It abstracts each provider’s API into a single interface and adds routing, fallbacks, key management, and caching, so swapping a model becomes a configuration change rather than a deployment.
LiteLLM leads open-source self-hosting. OpenRouter leads managed multi-model access. Portkey, Vercel AI Gateway, Cloudflare AI Gateway, Bifrost, and Kong AI Gateway fill out the field. A gateway makes routing decisions; observability measures what happened. The two are distinct concerns that increasingly ship in one product. Full treatment: What is an LLM gateway.
5. Memory: what does the agent remember?
Memory is persistent state an agent keeps across sessions or beyond the context window: facts it learned, decisions it made, relationships it tracked. It is distinct from retrieval-augmented generation, which searches a static corpus. Memory is the knowledge the agent itself accumulated.
Mem0 is the most widely adopted. Letta, formerly MemGPT, takes an operating-system-style tiered approach. Zep builds temporal knowledge graphs that track when a fact was true. LangMem, Cognee, and Supermemory take other routes. Full treatment: What is agent memory.
6. Guardrails: what is the agent allowed to say?
Guardrails constrain what a model is allowed to say or do at the level of an individual response: input validation, output filtering, jailbreak detection, PII redaction, structured-output enforcement. They govern the content of what flows through the model, not who is allowed to use it.
NeMo Guardrails from NVIDIA leads programmable open-source rails. Guardrails AI specializes in structured-output validation. Lakera, LLM Guard, Microsoft Guidance, Galileo Protect, and Arthur Shield occupy the rest of the category. Regulatory pressure, the EU AI Act among it, has moved guardrails from optional to required for many deployments. Full treatment: What are AI guardrails.
7. Human-in-the-loop: who signs off on risky actions?
Human-in-the-loop inserts human approval at specific decision points: before a high-stakes action, or when agent confidence is low. The three patterns are pre-execution approval, post-execution review, and exception-based escalation.
HumanLayer offers a decorator-based approval pattern with multi-channel routing. The OpenAI Agents SDK ships HITL primitives natively. Permit.io brings access-control-style policy to the same problem. The harder engineering question underneath is durable execution: letting an agent suspend for hours or days while it waits for a human, then resume cleanly. Full treatment: What is human-in-the-loop for AI agents.
8. Control plane: how do I run this fleet at scale?
A control plane governs what agents do at runtime, across a fleet: policy enforcement, budget caps, sensitive-action blocking, audit trails, multi-agent coordination. The distinction from observability is direction. Observability is passive and tells you what happened. A control plane is active and stops things from happening.
The category emerged over a few months in 2026. Galileo Agent Control, released open-source under Apache 2.0, along with Salesforce Agent Fabric, Microsoft Agent 365, and HumanLayer ACP, all shipped within months of one another. They are enterprise-first or infrastructure-heavy. Full treatment: What is an agent control plane.
9. Optimization: how do I spend less without losing quality?
Optimization, or token economics, is the discipline of tracking, attributing, and reducing the token cost of agent execution. It matters more than it used to because agents now run unattended for hours, and one agent stuck in a loop can spend a monthly budget in an afternoon.
The techniques are established: model cascading (the FrugalGPT pattern), prompt compression (LLMLingua), semantic caching (GPTCache), and prompt caching from the model providers. What is missing is assembly. The pieces are scattered across other layers rather than collected into one product. Full treatment: What is agent token economics.
Where the layers are converging
The nine layers have hard edges on paper and soft ones in practice. Several pairs are merging.
Gateways and observability were the first to converge. Helicone and Portkey are both. A gateway already sees every request and response, so adding measurement is a short step.
Observability and evaluation are converging next. Braintrust and Galileo span both, and several observability tools have added eval features. It makes sense: the trace you captured in production is the natural input to the eval you run offline.
Evaluation and environments are merging at the research end. HUD and the Prime Intellect Environments Hub treat an environment and its eval as one closed loop: run the agent, score it, feed the score into training, repeat.
Guardrails and the control plane are converging from the safety side. A guardrail blocks one bad response. A control plane halts an agent that keeps producing them. The first grows naturally toward the second.
Human-in-the-loop and the control plane are the closest pair of all. Approval primitives are most of what a control plane needs, and a HITL tool that adds policy and audit has effectively become one.
Where the gaps are
Two layers are visibly underbuilt.
Optimization, layer nine, is the most fragmented. Every individual piece exists somewhere. Caching lives in gateways. Model cascading and prompt compression live in research. Cost analytics live in observability tools. What does not exist is a single product that watches an agent’s traces, finds the token waste, and tells you (or applies) the change that saves the most without hurting quality. It is a named category with no clear product owner.
The control plane, layer eight, has the opposite problem. Products exist, and they cluster at one end of the market. Galileo Agent Control, Salesforce Agent Fabric, Microsoft Agent 365, and HumanLayer ACP are enterprise-first or infrastructure-heavy: vendor platforms, Kubernetes clusters, enterprise licensing. A control plane that installs in one line and runs locally, the way an observability agent or a linter does, is still uncommon.
The two gaps are connected. Optimization produces recommendations, and a control plane is where a recommendation becomes an enforced rule. “47 of your last 100 sessions would have completed on a cheaper model” is an interesting fact in an observability tool and an actual saving when a control plane can turn it into routing policy. Observation, then recommendation, then enforcement. The layers are drawn separately on the map. The value compounds when they connect.
The map has a shelf life
Treat all of this as accurate now and provisional by default. Two years ago, several of these nine layers were not categories. Two years from now, some will have merged and others will have split. The pattern repeats: the ecosystem fragments as new needs appear, then re-converges as products absorb the layers next to them.
The layers that are underbuilt today, optimization and the dev-first end of the control plane, are where the next round of consolidation is most likely. The nine questions in this map are durable. The arrangement of tools answering them is not, and whoever builds credibly into the gap layers during 2026 is working on the part of the stack that is still being drawn.
Common questions
- Why nine layers and not seven or eleven?
- The number is not sacred. The nine come from a simple test: each layer answers a question a production agent team actually asks, and each has at least one tool you would evaluate to answer it. Merge two and you lose a real distinction. Observability and the control plane look similar until an incident, when it matters that one only watched and the other could have intervened. Split one and you get categories too thin to have their own tools. Nine is the count where every layer earns its place, and it will change as the ecosystem does.
- Do all teams need all nine layers?
- No. Most teams need three or four. A team running one bounded agent needs observability and perhaps guardrails. The layer count rises with autonomy: the longer an agent runs unattended, with more tools and less supervision, the more of the stack it needs. Memory matters once agents span sessions. The control plane matters once you run a fleet. Optimization matters once the bill does. Adopt a layer when the pain it addresses shows up, not before.
- Which layer is most undeveloped right now?
- Optimization, layer nine. The techniques are well understood and the research is years old, and they have not been assembled into something a developer can adopt in an afternoon. The control plane, layer eight, is close behind: the products exist, and they skew enterprise. Both are covered in detail in their own posts.
- How fast is this changing?
- Fast enough that a map has a shelf life. The control-plane layer barely existed at the start of 2026 and had four credible entrants by mid-year. Benchmarks that looked solid were shown gameable within months. The nine questions are stable. The set of tools answering them turns over quickly, so treat the tool names here as a mid-2026 snapshot.
The full series
- Agents 101: Reasoning, Actions & Autonomy
- What is agent observability?
- What is OpenTelemetry, and why does it matter for AI agents?
- What is an LLM gateway?
- What is agent evaluation?
- What is agent memory?
- What are agent environments and sandboxes?
- What are AI guardrails?
- What is human-in-the-loop for AI agents?
- What is an agent control plane?
- What is agent token economics?